最近在写一个后端项目,主要的操作就是根据用户的前端数据,在后端打开项目中的代码文件,修改对应位置的参数,因为在目前的后端项目中经常使用这个操作,所以简单总结一下。
1. 文件路径:./test.c
2. 文件内容
……
case EPA:
chan_desc->nb_taps = 7;
chan_desc->Td = .410;
chan_desc->channel_length = (int) (2*chan_desc->sampling_rate*chan_desc->Td + 1 + 2/(M_PI*M_PI)*log(4*M_PI*chan_desc->sampling_rate*chan_desc->Td));
sum_amps = 0;
chan_desc->amps = (double *) malloc(chan_desc->nb_taps*sizeof(double));
chan_desc->free_flags=chan_desc->free_flags|CHANMODEL_FREE_AMPS ;
for (i = 0; i<chan_desc->nb_taps; i++) {
chan_desc->amps[i] = pow(10,.1*epa_amps_dB[i]);
sum_amps += chan_desc->amps[i];
}
for (i = 0; i<chan_desc->nb_taps; i++)
chan_desc->amps[i] /= sum_amps;
chan_desc->delays = epa_delays;
chan_desc->ricean_factor = 1;//待修改位置
chan_desc->aoa = 0;//待修改位置
chan_desc->random_aoa = 0;//待修改位置
chan_desc->ch = (struct complexd **) malloc(nb_tx*nb_rx*sizeof(struct complexd *));
chan_desc->chF = (struct complexd **) malloc(nb_tx*nb_rx*sizeof(struct complexd *));
chan_desc->a = (struct complexd **) malloc(chan_desc->nb_taps*sizeof(struct complexd *));
……
复制#1. 读取文件
path='./test.c'
with open(path, 'r') as file:
file_content = file.read()
复制chan_desc->ricean_factor = 1;//待修改位置为例,查找这句话的起点和终点。## 注:此步骤需要import re
#2. 查找文件替换位置
start_index=file_content.find('chan_desc->ricean_factor = ')#起点
end_index=file_content.find('chan_desc->aoa = ',start_index)#终点
if end_index==-1 or start_index==-1:
print('未找到待修改位置')
#此时得到的两个指针,分别指向了待修改位置的起点和终点,如下图所示:
复制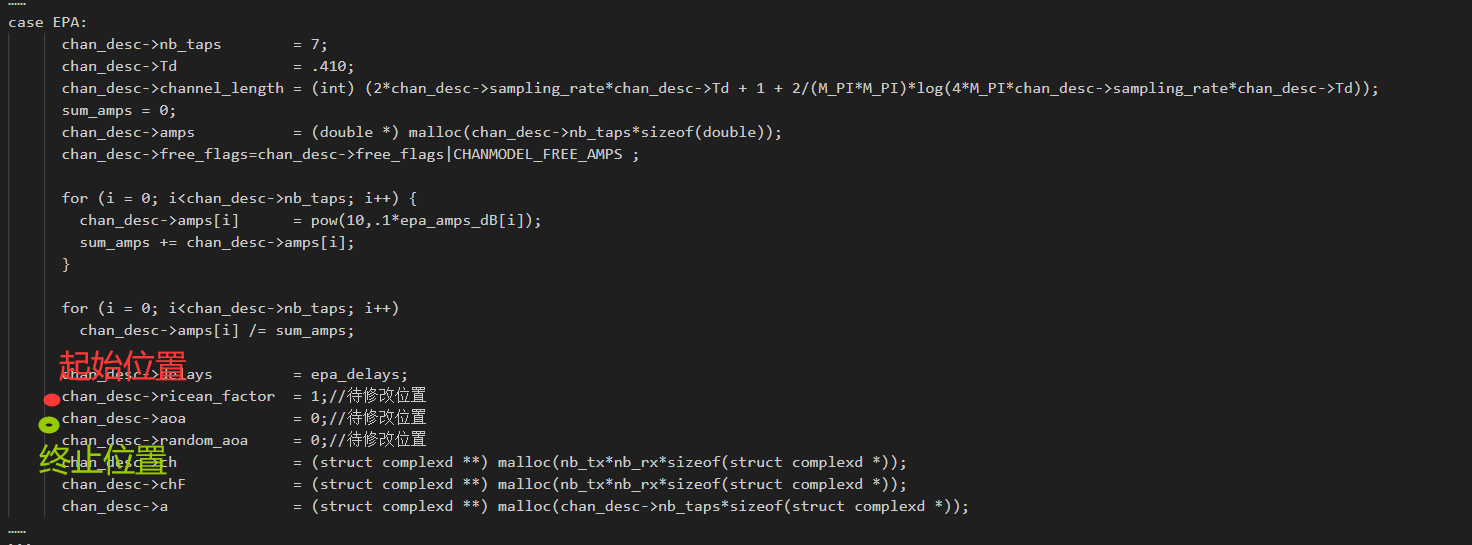
#3. 设置替换文件内容
ricean_factor=3#假设这是要修改的参数信息
updata_content=file_content[:start_index]#获取这行代码之前的内容
update_content+='chan_desc->ricean_factor = '+str(ricean_factor)+';//待修改位置'#修改这行代码
update_content+=file_content[end_index:]#获取这行代码之后的内容
#此时得到的update_content就是修改后的完整文件内容,只修改了ricean_factor这一行的值
复制#4. 写入文件
if update_content!="":#如果修改内容不为空
with open(path, 'w') as file:#w表示覆盖写入,之前的内容都会被覆盖
file.write(update_content)
复制import re
#1. 读取文件
path='./test.c'
with open(path, 'r') as file:
file_content = file.read()
#2. 查找文件替换位置
start_index=file_content.find('chan_desc->ricean_factor = ')#起点
end_index=file_content.find('chan_desc->aoa = ',start_index)#终点
if end_index==-1 or start_index==-1:
print('未找到待修改位置')
#3. 设置替换文件内容
ricean_factor=3#假设这是要修改的参数信息
updata_content=file_content[:start_index]#获取这行代码之前的内容
update_content+='chan_desc->ricean_factor = '+str(ricean_factor)+';//待修改位置'#修改这行代码
update_content+=file_content[end_index:]#获取这行代码之后的内容
#4. 写入文件
if update_content!="":#如果修改内容不为空
with open(path, 'w') as file:#w表示覆盖写入,之前的内容都会被覆盖
file.write(update_content)
复制try:
with open(file_path, "r") as file:
file_content = file.read()
except Exception as e:
return str(e)
# 设置改写内容
updated_content = ""
# 查找修改
start_index_1 = file_content.find("start_sentence")#要确保查找元素的唯一性
end_index_1 = file_content.find("end_sentence",start_index_1,)
if start_index_1 == -1 or end_index_1 == -1:
print("未找到待修改位置")
return -1
#
updated_content = file_content[:start_index_1]#获取这行代码之前的内容
updated_content += "start_sentence和end_sentence之间的sentence_1;\n"
updated_content += "start_sentence和end_sentence之间的sentence_2;\n"
updated_content +=file_content[end_index_1:]
##此时updated_content就是修改后的完整文件内容
if updated_content != "":
with open(file_path, "w") as file:
file.write(updated_content)
else:
print("修改失败")
return -1
复制try:
with open(file_path, "r") as file:
file_content = file.read()
except Exception as e:
return str(e)
# 设置改写内容
updated_content = ""
# 查找修改
start_index_1 = file_content.find("start_sentence_1")#要确保查找元素的唯一性
end_index_1 = file_content.find("end_sentence_1",start_index_1,)
start_index_2 = file_content.find("start_sentence_2",end_index_1)
end_index_2 = file_content.find("end_sentence_2",start_index_2,)
start_index_3 = file_content.find("start_sentence_3",end_index_2)
end_index_3 = file_content.find("end_sentence_3",start_index_3,)
start_index_4 = file_content.find("start_sentence_4",end_index_3)
end_index_4 = file_content.find("end_sentence_4",start_index_4,)
if (
start_index_1 == -1
or end_index_1 == -1
or start_index_2 == -1
or end_index_2 == -1
or start_index_3 == -1
or end_index_3 == -1
or start_index_4 == -1
or end_index_4 == -1
):
print("未找到待修改位置")
return -1
#
updated_content = file_content[:start_index_1]#获取这行代码之前的内容
updated_content += "start_sentence_1和end_sentence_1之间的内容"
updated_content +=file_content[end_index_1:start_index_2]
updated_content += "start_sentence_2和end_sentence_2之间的内容"
updated_content +=file_content[end_index_2:start_index_3]
updated_content += "start_sentence_3和end_sentence_3之间的内容"
updated_content +=file_content[end_index_3:start_index_4]
updated_content += "start_sentence_4和end_sentence_4之间的内容"
updated_content += file_content[end_index_4:]
##此时updated_content就是修改后的完整文件内容
if updated_content != "":
with open(file_path, "w") as file:
file.write(updated_content)
else:
print("修改失败")
return -1
复制