今天主要介绍的是Redis数据结构和底层数据类型
在之前的Redis基本概念讲解中,我们知道Redis的存储单位是键值对。
其中,键key只能是字符串类型,而值value则支持丰富的数据类型,包括基本数据类型和特殊数据类型。
字符串类型,容量大小不超过512MB。主要存储内容为三类:
应用场景:缓存、计数器、session共享等。
相关命令:
之前我们提到过Redis的存储单位是键值对,hash指的是值本身又是一个键值对。
应用场景:缓存、存储对象信息等。
相关命令:
- hset key field value:根据key查找指定键,这个键的值是一个哈希表,添加键值对field:value
- hget key field:根据key查找指定键,这个键的值是一个哈希表,获取键field对应的值
- hgetall key:根据key查找指定键,这个键的值是一个哈希表,获取哈希表中所有的键值对
- hdel key field:根据key查找指定键,这个键的值是一个哈希表,删除键field对应的键值对
在Redis中使用双端链表实现list,列表的插入和删除可以引申出栈、队列等特殊的数据结构。
应用场景:消息队列、时间列表等。
相关命令:
通过哈希表实现set,不允许重复元素。
应用场景:共同好友、共同关注等。
相关命令:
通过压缩列表或者跳跃表实现Zset,在第二部分会讲到。Zset不允许重复元素,但是每个元素都会关联一个double类型的分数,表示权重。元素本身不能重复,但是double类型的分数可以重复。Zset中的成员,根据分数从小到大排序。
应用场景:排行榜、带权重的消息队列等。
相关命令:
位图数据结构,操作二进制位进行记录,每一位都只有0·1两种状态,可以节省存储空间。
应用场景:统计用户的签到情况、统计用户的在线情况等。(今日已签/未签、今日在线/不在线)。
相关命令:
拥有基数统计的数据结构,基数指的是集合中去掉重复数字之后的元素个数。基数统计指的是在误差允许范围内估算一组数据的基数,而不需要对数据进行全量统计。这样做的好处就是可以节省大量的内存空间。
应用场景:统计网站的UV(独立访客)、注册ip数、在线用户数、共同好友数等等
相关命令:
本身是使用zset实现的,存储的是经纬度信息,可以用来计算两个地理位置之间的距离。
应用场景:地图检索的相关场景
相关命令:
Stream这个数据结构,乍一看很像是文件读写时产生的流,但是实际上,这个数据结构和消息队列的实现有关。
Redis中消息队列的实现方式为发布订阅pub/sub,但是无法记录历史信息,而Stream支持消息持久化和主备到。
Redis中Stream的数据结构如下所示:
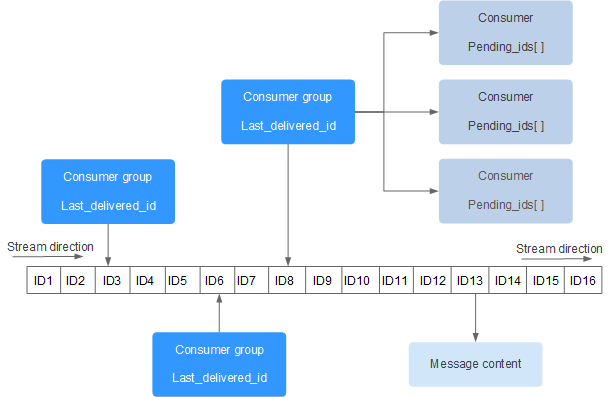
其中:
消息队列的实现是绑定的。相关命令:
*表示redis自动生成,自定义需要保证递增性,
XADD mystream * field1 A field2 B field3 C field4 D:在mystream对应的消息队列中添加多条消息,消息id自动生成,消息内容为field1:A field2:B field3:C field4:DXLEN mystream:获得mystream对应的消息队列的长度XTRIM mystream MAXLEN 2:修剪mystream对应的消息队列,限制长度为2XDEL mystream 1538561700640-0:在mystream对应的消息队列中删除id为1538561700640-0的消息 XRANGE writers - + COUNT 2:按照id从小到大的顺序,在writer对应的消息队列中返回2个消息记录-和+表示最小值和最大值,只返回2个消息记录;XREVRANGE writers + - COUNT 1:按照id从大到小的顺序,在writer对应的消息队列中返回一个消息记录XREAD COUNT 2 STREAMS mystream writers 0-0 0-0:从mystream、writers中分别读取id为0-0的消息,返回消息列表XGROUP CREATE key groupname id-or-$:在键值为key的值部分创建消费组,如果不存在key对应的表项则创建,消费组名为groupname,id-or-$决定消费方向,如果id为0-0,则表示从头开始读取消息,如果id是$,表示从尾部开始消费
XGROUP CREATE mystream group1 0-0:在mystream对应的消息队列中创建消费组group1,从头开始消费XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]:在key对应的消息队列中,消费组名为group,消费者名为consumer,该消费者读取消息队列中对应id的信息,读取数量为count,milliseconds表示阻塞时间
XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >XACK key group id:被group对应的消费组处理的指定id的消息标记为"已读"XGROUP SETID key groupname id-or-$:在键值为key对应的消息队列,指定名为groupname的消息队列进行游标移动,id-or-$决定消费方向,如果id为0-0,则表示从头开始读取消息,如果id是$,表示从尾部开始消费XGROUP DELCONSUMER key groupname consumername:删除对应键值的消息队列中名为groupname的消费者组中,名为consumername的消费者XGROUP DESTROY key groupname:删除对应键值的消息队列中名为groupname的消费者组XPENDING key group:显示对应键值的对应消费组中待处理消息的信息列表,这些信息已经被读取,但是还没有被确认XCLAIM key group consumername milliseconds ID:转移消息归属权,类似于传递数据,键值key对应的消息队列,将对应id的信息转移到消费者组group中对应的消费者consumername中,milliseconds表示阻塞时间,超过这个时间才开始转移XINFO GROUPS groupname:打印对应消费者组信息XINFO STREAM key:打印对应流信息XINFO CONSUMERS key groupname:打印对应消费者组中消费者信息在前文中,我们了解到Redis的基本存储单位是键值对,其中value部分支持丰富的数据类型,包括五个基本类型以及Bitmap、hyberloglog、geo、stream等特殊类型,不同的数据类型有不同的使用场景,因此Redis的功能十分强大。而这些丰富的数据类型,每个对象都是有两部分组成的:
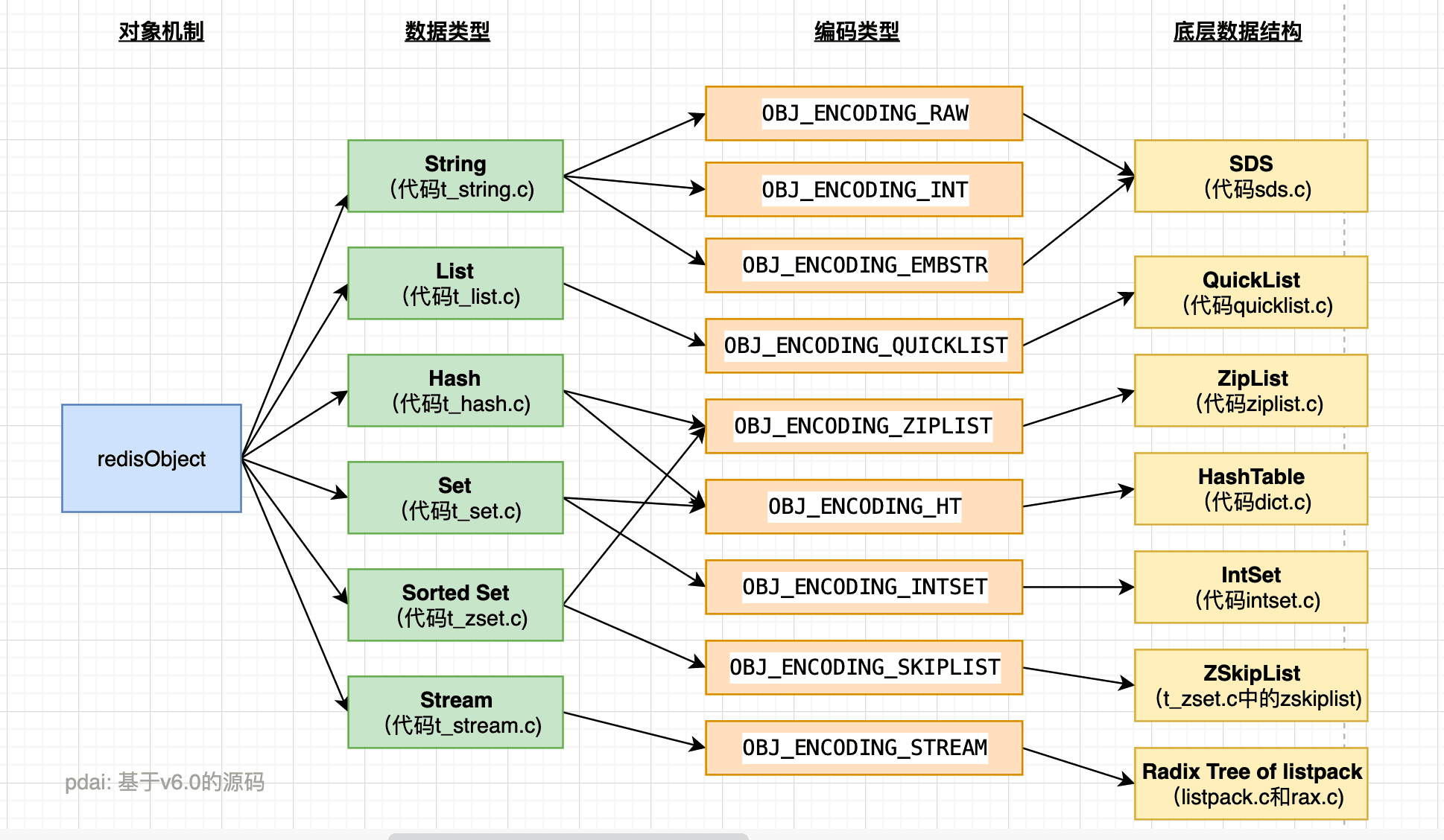
而Redis为什么要多此一举,在实现数据类型之后,又要另外构建一套底层数据结构呢?
在之前的介绍中,我们介绍了很多相关的命令,其中很多都是基于键查找值对象,而有的命令是某个值对象特有的,例如LPUSH和LLEN等只用于列表,SADD只作用于集合,因此,为了方便这些命令的执行,需要让每个键都带有类型信息,从而让程序选择合适的处理方式。
简单来说,就是Redis相关操作命令的多态性决定了Redis需要底层数据结构的支持。
存储二进制数据的动态扩容字符串,整体由三部分组成:
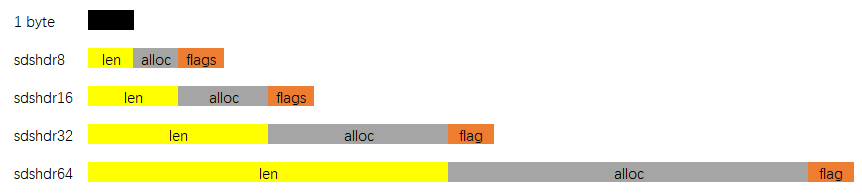
len表示字符串的长度,flags表示头部的类型,使用最后三位,alloc表示头部和\0之外的字节数\0和C语言中的字符串相比,SDS的优势在于:
len参数即可获得字符串长度,时间复杂度为O(1)。len检查内存空间是否满足,如果不足会进行内存扩展alloc记录字节数,供后续使用\0结尾,因此可以使用C语言字符串的大部分函数,例如strlen、strcat、strcpy等是一种双向链表,节点为ziplist(压缩链表)的形式:
这里定义了6个结构体:
是一种哈希表,使用链地址法解决哈希冲突。
如图展示的是内存的分配情况:
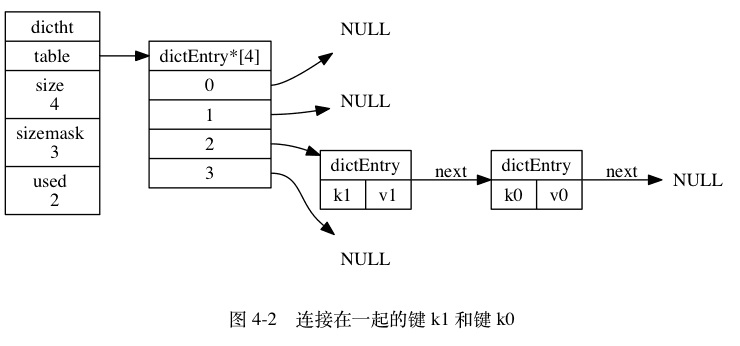
table是一个数组,每个元素都是一个数值存放节点。
每个节点都是一个dictEntry结构体,其中key和value都是一个指针,指向实际存储的数据。
源代码如下所示:
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于 size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry
跳跃表实际应用中主要作为有序列表使用,但是性能比一般的有序列表更优。
源码定义如下所示:
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
设计思路为:
头节点不持有任何数据, 且其level[]的长度为32
每个结点包括如下几个字段:
和平衡树、哈希表等元素相比,跳跃表需要更大的存储空间,打死你性能更优;在范围查找上有相当的优势,且插入和删除更简单,算法实现也更容易。
encoding 表示编码方式,的取值有三个:INTSET_ENC_INT16, INTSET_ENC_INT32, INTSET_ENC_INT64
length 代表其中存储的整数的个数
contents 指向实际存储数值的连续内存区域, 就是一个数组;整数集合的每个元素都是 contents 数组的一个数组项(item),各个项在数组中按值得大小从小到大有序排序,且数组中不包含任何重复项。(虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组,但实际上 contents 数组并不保存任何 int8_t 类型的值,contents 数组的真正类型取决于 encoding 属性的值)
整数集合的升级
当存储int64的整数集合添加一个int32的元素,会导致集合中所有元素转变为int32类型,按照新元素的类型进行扩容和空间分配,将现有元素转变为新类型,之后改变encoding的值(对应存储元素的类型),并且length+1(表示加入一个新元素)。
是一种双向链表,可以存储字符串或整数(二进制形式)。
整体由5部分组成:
65535表示entry个数未知,此时确认ziplist的长度需要遍历整个ziplist;prevlen + encoding + entry-dataprevlen + encoding0xFF,用于标记ziplist的结尾。和一般的数组相比,ziplist的优势在于:
同样也是因为节省内存,不浪费一点内存的思路,导致ziplist的缺点也很明显:
Q:Redis的数据结构
A:从基本数据类型、特殊数据类型、底层数据结构三个方面回答
Q:为什么Redis使用的是哈希索引
A:内存键值数据库采用哈希表作为索引,很大一部分原因在于,其键值数据基本都是保存在内存中的,而内存的高性能随机访问特性可以很好地与哈希表O(1)的操作复杂度相匹配。
Q:Redis字符串底层和查询过程用的哪些数据结构
A:底层查询的过程中会涉及到跳跃表的使用。