Node.js 是2009的时候由大神 Ryan Dahl 开发的。Ryan 的本职工作是用 C++ 写服务器,后来他总结出一个经验,一个高性能服务器应该是满足“事件驱动,非阻塞 I/O”模型的。C++ 开发起来比较麻烦,于是 Ryan 就想找一种更高级的语言,以便快速开发。
Ryan 发现 JS 语言本身的特点就是事件驱动并且是非阻塞 I/O 的,跟他的思路正是绝配。第二点,Chrome 的 JS 引擎,也就是 V8 引擎是开源的,而且性能特别棒。于是 Ryan 就基于 V8 开发了 Node.js。
在 Node.js 出现之前,最常见的 JavaScript 运行时环境是浏览器(我们平时写的代码跑在浏览器环境中)。浏览器为 JavaScript 提供了 DOM API,2009 年初 Node.js 出现了,它是由 Ryan Dahl 基于 Chrome V8 引擎开发的 JavaScript 运行时环境,所以 Node.js 也是 JavaScript 的一种宿主环境。
Node.js 不是浏览器,所以它不具有浏览器提供的 DOM API,比如 Window 对象、Location 对象、Document 对象、HTMLElement 对象、Cookie 对象等等。但是,Node.js 提供了自己特有的 API,比如全局的 global 对象,也提供了当前进程信息的 Process 对象,操作文件的 fs 模块,以及创建 Web 服务的 http 模块等等。这些 API 能够让我们使用 JavaScript 操作计算机,也可以开发 web 服务器。
官方定义:Node.js 是一个开源和跨平台的 JavaScript 运行时环境。
怎么理解这个 JavaScript 运行时环境 ?顾名思义,是一个可以运行 JavaScript 的环境。这里的环境主要包含以下两个方面:
前者是由 Chrome V8 引擎提供的,而后者则是由一个底层由 C,C++ 编写的高性能的事件驱动的异步 I/O 库 libuv 所提供。
Node.js 内置的模块很丰富,具体可以查看nodejs 官网
通俗理解:nodejs 能让js 代码在浏览器之外执行,且能与操作系统进行交互、能操作文件、操作网络等。
在nodejs 这个执行环境中,我们可以与操作系统进行通信、能控制计算机,通过这个平台做很多的事情,如写一些web服务,客户端工具软件、打包工具等等。有了这样的一个平台,我们干的事情相比只能依赖在浏览器中完全不是一个级别的。
nodejs 正式发布的时候,JavaScript 还没有标准的模块机制,nodejs一开始采用了CommonJS规范。后面JavaScript 标准的模块机制ES Modules诞生,浏览器开始逐步支持ES Modules。Node.js 从v13.2.0之后也引入了规范的ES Modules机制,同时兼容早期的CommonJS。
现在我们写 Node.js 模块的时候,可以有 3 种方式:
模块化的目的是使代码可以更好地复用,同时为了更方便的使用别人写的模块或者分享自己的模块。推出了包管理工具,我们叫他npm,它允许我们以包的形式从共享仓中发布和下载模块。
NPM 的全称是Node Package Manager,是一个将 Node.js 的模块以包的形式组织和管理的工具。
NPM Scripts 是指在package.json文件中配置scripts属性,在其中指定脚本命令:
// package.json
{
... //其他配置
"scripts": {
"eslint": "eslint ziyue.js"
}
}复制NPM Scripts 能够执行对应的 Node 命令,是因为 NPM 在安装模块的时候,不仅将模块自身安装到node_modules目录下,还会在node_modules目录下创建一个.bin的子目录,将模块包中的命令行脚本安装到.bin目录下,并在 NPM Script 执行时设置系统的环境变量 PATH 包含node_modules/.bin目录,这样就能够正常执行脚本了。
如执行:
npm run eslint复制
就相当于执行了:
node ./node_modules/.bin/eslint xx.js复制
作为前端工程师,少不了要和 Web 打交道。通常情况下,前端工程师主要负责“端”的部分,也就是浏览器这一头的功能实现,后端工程师负责另一头,也就是服务器上的逻辑实现。当我们打开一个网页的时候,浏览器会向服务器发送 HTTP 请求,服务器根据请求的内容处理数据,将正确的数据返回。可以说,HTTP 协议将浏览器与服务器连接在了一起。
因为 Web 开发中的许多问题既与客户端有关也与服务端有关,所以前端工程师很有必要了解 HTTP 协议。比如要优化性能,加快页面的打开速度,就需要理解 TCP 协议和 HTTP 协议,理解连接是如何建立的,数据是如何传输的。有兴趣可以参考之前记录的 http 相关知识点
浏览器可以处理多种格式的媒体文件,遵循的标准叫做 MIME。
MIME 标准以type/subtype,即主类型/子类型,来表示一个文件的格式。MIME 类型对大小写不敏感,通常都写成小写形式。
HTTP 请求常见的主类型如下:
|
类型 |
描述 |
典型示例 |
|
text |
表明文件是普通文本,理论上是人类可读 |
text/plain, text/html, text/css, text/javascript |
|
image |
表明是某种图像。不包括视频,但是动态图(比如动态 gif)也使用image类型 |
image/gif, image/png, image/jpeg, image/bmp, image/webp, image/x-icon |
|
audio |
表明是某种音频文件 |
audio/midi, audio/mpeg, audio/webm, audio/ogg, audio/wav |
|
video |
表明是某种视频文件 |
video/webm, video/ogg |
|
application |
表明是某种二进制数据 |
application/octet-stream, application/pkcs12, application/vnd.mspowerpoint, application/xhtml+xml, application/xml, application/pdf |
浏览器的请求头中的 Accept 字段包含该请求期望的 MIME type,可以有多个,以逗号分隔。
所以,Accept: image/webp,image/apng,image/*,*/*;q=0.8表示浏览器期望的格式依次是image/webp、image/apng、image/*、*/*。 MIME 类型支持通配符*,最后的q=0.8表示相对品质因子,也就是说客户端“期望”是这个类型的权重,这个值给服务器参考,如果有多个可能返回的类型带有品质因子,服务器优先返回品质因子大的类型。
静态资源文件一般不会变化,所以当客户端请求过某个文件之后,浏览器可以将这个文件缓存下来。这么做可以节省 HTTP 请求,既能够降低服务器的带宽消耗,也能够提升用户的访问速度。在 HTTP 协议中,动作 GET 和 OPTIONS 是支持缓存的。
浏览器支持两种标准的缓存策略:强缓存和协商缓存。
浏览器缓存策略根据响应头的cache-control 来控制。
Cache-Control 通用消息头字段,被用于在 http 请求和响应中,通过该字段来实现缓存机制。
通俗理解:告诉浏览器,当前这个资源要怎么缓存。
只有浏览器可以缓存。服务器返回资源的时候带有Cache-Control响应头,这个策略叫做强缓存。
响应头只要带有cache-control 就使用强缓存策略,当然值不能是no-store(不进行缓存)
Cache-Control响应头的最常用格式为:
Cache-Control: max-age=<seconds>复制
其中 seconds 是缓存的时间,单位是秒。
当浏览器请求资源得到的响应带有Cache-Control响应头时,浏览器会将该资源缓存到本地。当浏览器下一次访问该资源时,同时满足以下 3 个条件,浏览器会直接使用本地的资源,不发起 HTTP 请求:
host、pathname、query)GETCache-Control: no-cache和Pragma: no-cache这两个信息 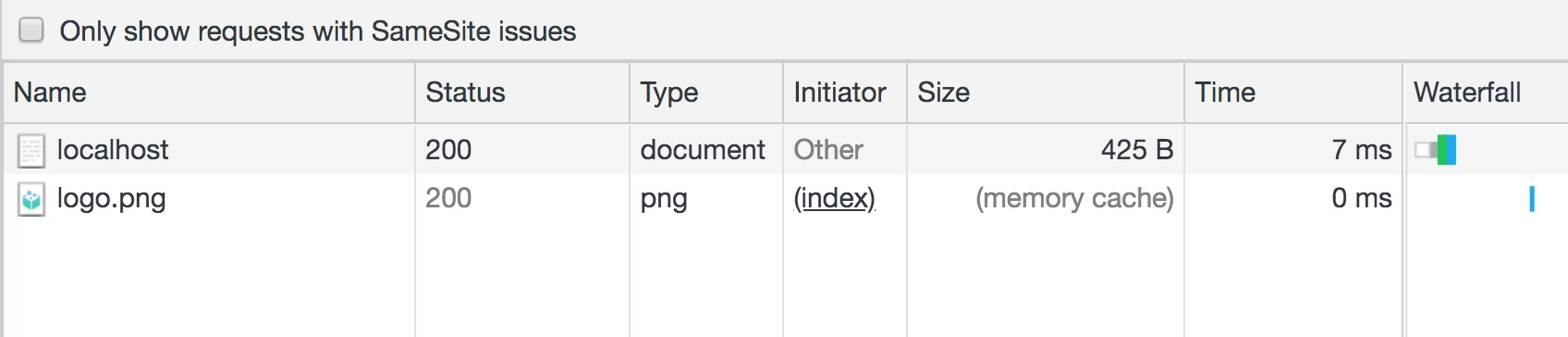
协商缓存,以 HTTP 内容协商的方式来实现的缓存。协商缓存规定,浏览器发起 HTTP 请求时,服务器可以返回Last-Modified响应头,这个响应头的值是一个时间戳。如果服务器这么做了,那么浏览器会缓存这个资源,并且在今后请求该资源的时候,会带有if-modified-since请求头,它的值是上一次Last-Modified响应头中的时间戳。
服务器收到带有if-modified-since请求头的请求,根据请求头中的时间戳,对文件进行判断,如果文件内容在该时间戳之后到当前时间里没有被修改,那么服务器返回一个 304 响应,该响应表示只有 HEAD 没有 BODY。浏览器如果收到 304 响应,就会以缓存的内容作为 BODY。
除来Last-Modified响应头,还有一个 Etag 响应头,它的机制和Last-Modified大同小异,只是把Last-Modified的时间戳换成Etag签名,相应地把If-Modified-Since字段换成If-None-Match字段,其中Etag的值可以用资源文件的 MD5 或 sha 签名。
协商缓存为什么要有两种呢?
因为,有时候我们的网站是分布式部署在多台服务器上,一个资源文件可能在每台服务器上都有副本,相应地资源文件被修改时候,新的文件要同步到各个服务器上,导致各个文件副本的修改时间不一定相同。那么当用户一次访问请求的服务器和另一次访问请求的服务器不同时,就有可能因为两个文件副本的修改时间不同而使得Last-Modified形式的协商缓存失效。
如果这种情况采用Etag形式的协商缓存,根据文件内容而不是修改时间来判断缓存,就不会有这个问题了。
通过地址栏访问、以及强制刷新网页的时候,HTTP 请求头自动会带上Cache-Control: no-cache和Pragma: no-cache的信息。只要有这两个请求头之一,浏览器就会忽略响应头中的Cache-Control字段,即忽略强缓存。
因为强制刷新会带上Cache-Control: no-cache和Pragma: no-cache请求头且不会带上If-Modified-Scene和If-None-Match请求头,意思是不使用缓存,忽略缓存。
no-cache 不进行强缓存,走协商缓存,而max-age=0是进行强缓存,但是过期了,需要更新。虽然实际上看起来两者效果是一样的。
一般是缓存到内存以及硬盘
强缓存标识符:响应头的cache-control: 不是no-store,强缓存的状态码是200,带上from memory cache/from disk memory
协商缓存标识符:
响应头的带有 Last-Modified,表示缓存起来,下次请求带上If-Modified-Since,值是上次 Last-Modified的值。
响应头的带有 ETag,表示缓存起来,下次请求带上If-None-Match,值是上次 ETag的值。
(1)如果一致说明文件内容没有发生变化,直接返回304;
(2)如果不一致返回200 + 最新资源 + 最新的 ETag字符串。
Cache-Control: no-cache和Pragma: no-cache请求头且不会带上If-Modified-Scene和If-None-Match,意思是不使用缓存,忽略缓存。

Node.js的结构大致分为三个层次:
Node Standard Library是我们每天都在用的标准库、api,如 Http、Buffer、fs 等模块。它们都是由 JavaScript 编写的,可以通过require(..)直接能调用。Node Bindings是沟通 JS 和 C++ 的桥梁,封装 V8 和 Libuv 的细节,向上层提供基础API服务。这一层是支撑 Node.js 运行的关键,由 C/C++ 实现。第三层是支撑 Node.js 运行的关键,由 C/C++ 实现。
V8是 Google 开发的 javascript 引擎,为 javascript 提供了在非浏览器端运行的环境,可以说它就是 Node.js 的发动机。它的高效是 Node.js 之所以高效的原因之一。
Libuv为Node.js提供了跨平台,线程池,事件池,异步 I/O 等能力,是Node.js如此强大的关键。
C-ares提供了异步处理 DNS 相关的能力。
http_parser、OpenSSL、zlib等,提供包括 http 解析、SSL、数据压缩等其他的能力。