在面试中我相信有很多朋友会被问到 truncate 和 delete 有什么区别 ,这是一个很有意思的话题,本篇我就试着来回答一下,如果下次大家遇到这类问题,我的答案应该可以帮你成功度过吧。
从宏观角度来说, delete 是 DML 语句, truncate 是 DDL 语句,这些对数据库产生破坏类的语句肯定是要被 sqlserver 跟踪的,言外之意就是在某些场景下可以被回滚的,既然可以被 回滚,那自然就会产生 事务日志,所以从 事务日志 的角度入手会是一个好的办法。
为了方便测试,还是用上一篇的 post 表,创建好之后插入10条记录,参考sql如下:
DROP TABLE dbo.post;
CREATE TABLE post (id INT IDENTITY, content CHAR(1000) DEFAULT 'aaaaaa')
INSERT post DEFAULT VALUES
GO 10
有了数据之后就可以通过 fn_dblog 函数从 MyTestDB.ldf 中提取事务日志来观察 delete 和 truncate 日志的不同点。
为了观察 delete 产生的日志,这里用 @max_lsn 记录一下起始点,参考sql如下:
DECLARE @max_lsn VARCHAR(100)
SELECT @max_lsn=[Current LSN] FROM fn_dblog(NULL,NULL)
DELETE FROM post;
SELECT * FROM fn_dblog(NULL,NULL) WHERE [Current LSN] >@max_lsn
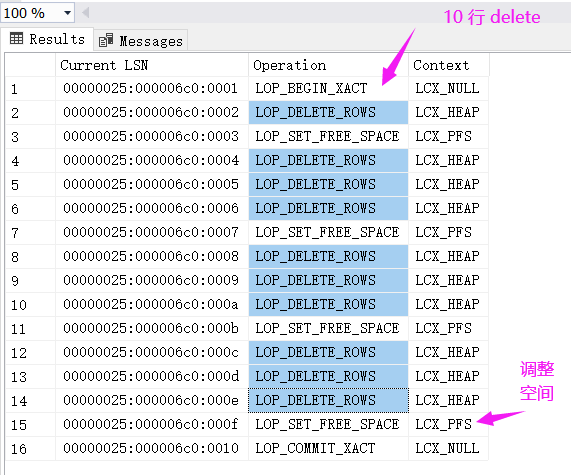
从事务日志看, delete 主要做了两件事情。
这里就有一个好奇的地方了,sqlserver 是如何执行删除操作的呢?要回答这个问题需要到数据页上找答案,参考sql如下:
DBCC IND(MyTestDB,post,-1)
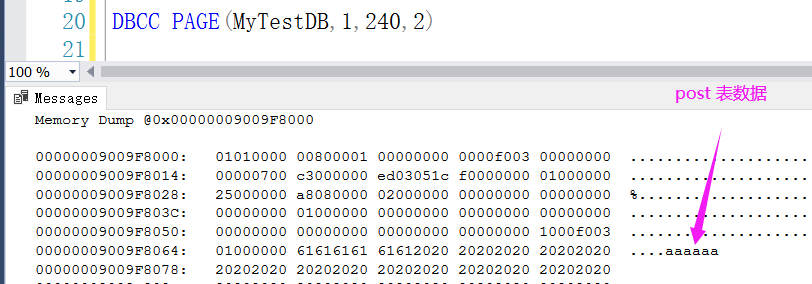
DBCC PAGE(MyTestDB,1,240,2)
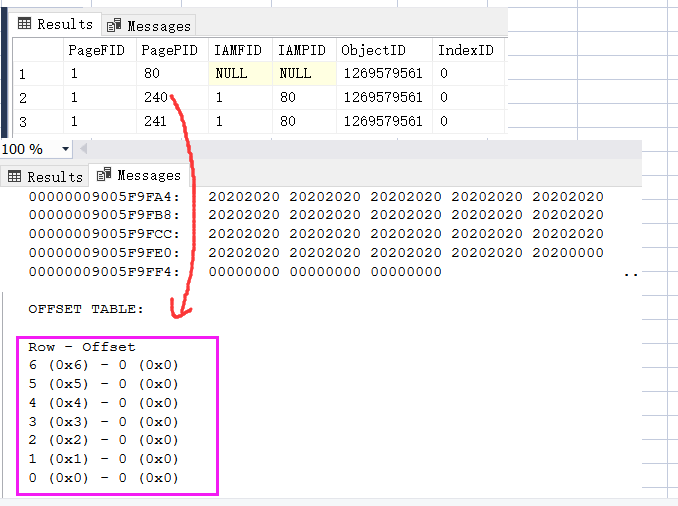
从图中可以得到如下两点信息, 至少在堆表下 delete 操作并没有删除 Page,第二个是 delete 记录删除只是将 slot 的指针 抹0 。
有些朋友可能要问,为什么还有对 PFS 的操作呢?很简单它就是用来记录当前页面的 占用空间比率 的,可以看下我的上一篇文章。
delete 原理搞清楚之后,接下来看下 truncate 做了什么?参考sql 如下:
DROP TABLE dbo.post;
CREATE TABLE post (id INT IDENTITY, content CHAR(1000) DEFAULT 'aaaaaa')
INSERT post DEFAULT VALUES
GO 10
DECLARE @max_lsn VARCHAR(100)
SELECT @max_lsn=[Current LSN] FROM fn_dblog(NULL,NULL)
TRUNCATE TABLE dbo.post
SELECT [Current LSN],Operation,Context,AllocUnitName FROM fn_dblog(NULL,NULL) WHERE [Current LSN] >@max_lsn
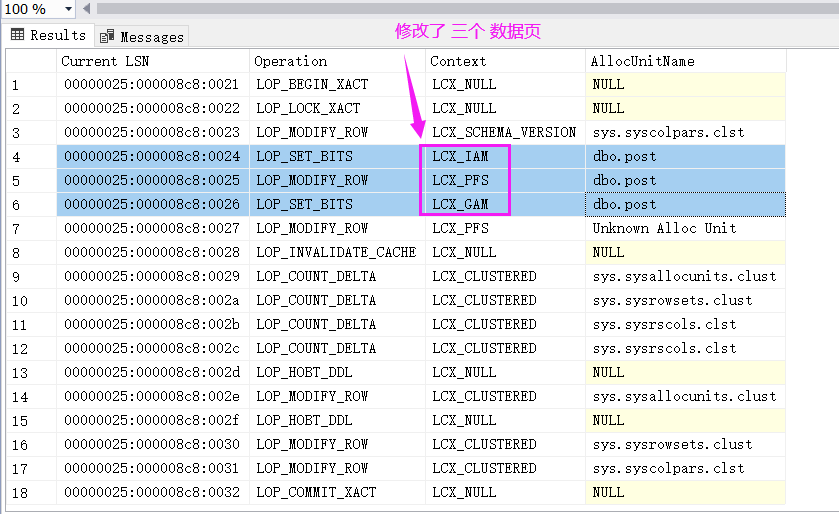
从图中可以看到,truncate 主要是对 IAM, PFS, GAM 三个空间管理数据页做了修改,并没有涉及到 PAGE 页,那就有一个疑问了,我的PAGE页还在吗?可以用 DBCC IND 看下。
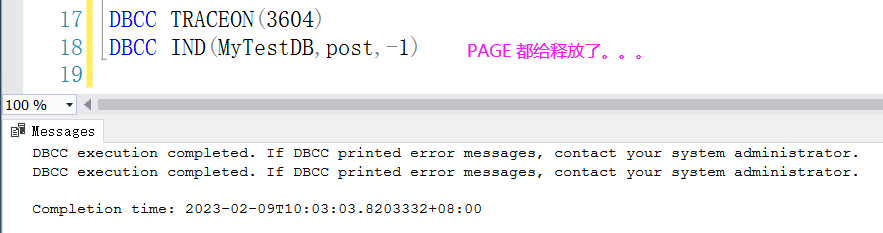
我去,truncate 操作居然把我的 PAGE 页给弄丢了,它是怎么实现的呢? 要想找到答案,大家可以想一想, truncate 是一个 DDL 语句,为了快速释放表数据,它干脆把 post 和 page 的关系给切断了,如果大家有点懵,画个图大概就是下面这样。
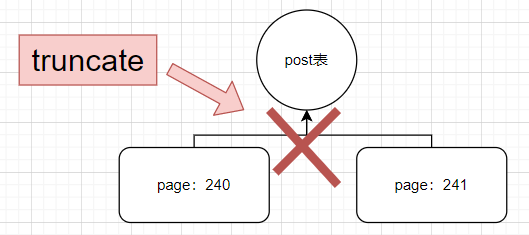
为了验证这个结论,可以用 DBCC PAGE 直接导出 240 号数据页,观察下是不是表中的数据,不过遗憾的是,这个数据页已不归属 post 表了。。。
接下来又得回答另外一个问题,sqlserver 是如何切断的? 这里就需要理解 GAM 空间管理机制。
GAM 是用来跟踪 区分配 状态的数据页,它是用一个 bit 位跟踪一个 区, 在数据库中一个区表示 连续的8个数据页,在 GAM 数据页中,用 1 表示可分配的初始状态,用 0 表示已分配状态,可能大家有点懵,我再画个简图吧。

为了让大家眼见为实,还是用 post 给大家做个演示。
DROP TABLE dbo.post;
CREATE TABLE post (id INT IDENTITY, content CHAR(1000) DEFAULT 'aaaaaa')
INSERT post DEFAULT VALUES
GO 10
DBCC TRACEON(3604)
DBCC IND(MyTestDB,post,-1)

从图中可以看到,post 表分配的数据页是 240 和 241 号,对应的区号就是 240/8 + 1 = 31,因为 GAM 是用 1bit 来跟踪一个区,所以理论上 GAM 页面偏移 31bit 的位置就标记了该区的分配情况。
这么说可能大家又有点懵,我准备用 windbg 来演示一下,首先大家要记住 GAM 是 mdf 文件中的第三个页面,用 2 表示, 前两个分别是 文件头 和 PFS 页,关于页面的首地址可以用 DBCC PAGE(MyTestDB,1,2,2) 导出来。
0:078> dp 00000009009F8000 +0x60
00000009`009f8060 00000000`005e0000 00000000`00000000
00000009`009f8070 00000000`00000000 00000000`00000000
00000009`009f8080 00000000`00000000 00000000`00000000
00000009`009f8090 00000000`00000000 00000000`00000000
00000009`009f80a0 00000000`00000000 00000000`00000000
00000009`009f80b0 00000000`00000000 00000000`00000000
00000009`009f80c0 d0180000`00001f38 ffffffff`ffffffd1
00000009`009f80d0 ffffffff`ffffffff ffffffff`ffffffff
从输出内容看,那个 0x1f38 就是 bitmap 数组的长度,后面就是 bit 的占用情况,因为在 31 bit 上,我们观察一个 int 就好了,输出如下:

从图中可以看到,全部都是 0 也就说明当前都是分配状态,如果是 1 表示未分配,接下来把 post 给 truncate 掉再次观察 GAM 页。
TRUNCATE TABLE dbo.post;
DBCC PAGE(MyTestDB,1,2,2)
输出如下:
0:117> dp 00000009009F8000+0x60
00000009`009f8060 00000000`005e0000 00000000`00000000
00000009`009f8070 00000000`00000000 00000000`00000000
00000009`009f8080 00000000`00000000 00000000`00000000
00000009`009f8090 00000000`00000000 00000000`00000000
00000009`009f80a0 00000000`00000000 00000000`00000000
00000009`009f80b0 00000000`00000000 00000000`00000000
00000009`009f80c0 d0184000`00001f38 ffffffff`ffffffd1
00000009`009f80d0 ffffffff`ffffffff ffffffff`ffffffff
对比之后会发现由原来的 000000001f38 变成了 400000001f38,可以用 .format 来格式化下。
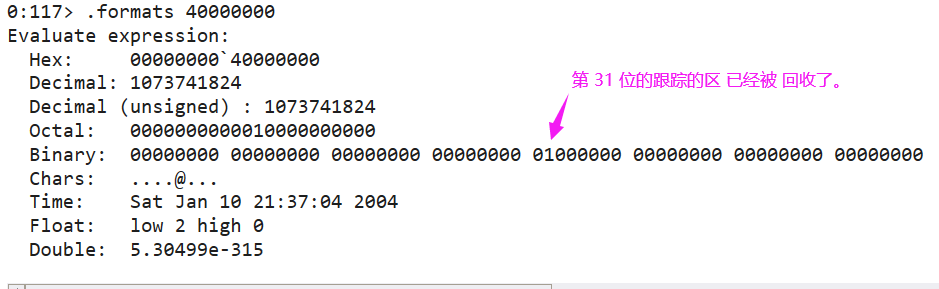
从图中看 31bit 跟踪的第 31 号区被回收了,也就验证了真的切断了联系。
同样的道理 PFS 偏移的 0n240 位置跟踪的这个页面也是被释放状态。

总的来说,delete 操作是将数据页中的每个 slot 指针一条一条的擦掉,每次擦除都会产生一条事务日志,所以对海量数据进行 delete 会产生海量的事务日志,导致你的 日志文件 暴增。而 truncate 是直接切断 post 和 page 的联系,只需要修改几个空间管理页的 bit 位即可。
最后的建议是如果要清空表数据,建议用 truncate table 。