两个函数的返回值都是一个新的Stream,但是接收类型 peek是Consumer,map是Function
使用场景:
对象数组的集合流, peek 为遍历数组, 对item进行处理; map为获取出某个属性或对整个item进行处理后返回
参考:
Java Stream peek vs. map
Java 8 Stream Api 中的 peek 操作
HashMap、TreeMap和LinkedHashMap
LinkedHashMap按照访问顺序: Map<String, Integer> map = new LinkedHashMap<>(16, 0.75f, true);, 默认情况下LinkedHashMap的访问顺序是关闭的(即accessOrder为false), 开启后会通过map.get("a")使a到最后, 前提是a存在.
hutool中的Dict继承了LinkedHashMap, 但是没有给出accessOrder的设置(目前5.8.6是)
TreeMap: 默认比较器是键1.compareTo(键2), 也即键的自然顺序.
HashMap转TreeMap来排序:
MapUtil.sort(map);map中的值(也即将map当作字典表去比较的), 也即当往sort中put的时候map中必须要有这个键, 不然.getCode()时候会有空异常, 也可以在比较器中给value一个默认值(如果可以让没有的在最前面, 如果默认指给得最大会遍历整个map来确定排在最后)Map<String, R<String>> map = new TreeMap<>();
map.put("apple", R.ok());
map.put("banana", R.param());
map.put("orange", R.fail());
TreeMap<String, R<String>> sortMap = new TreeMap<>(Comparator.comparing(p ->
Integer.parseInt(map.get(p).getCode())));
sortMap.putAll(map);
System.out.println("sortMap = " + JSONUtil.toJsonStr(sortMap));
区别
内部数据结构:
HashMap:使用数组和链表(JDK 8之前)或者数组和红黑树(JDK 8及以后)的组合来存储键值对。
TreeMap:使用红黑树作为内部数据结构,以保持键的有序性。
LinkedHashMap:使用哈希表和双向链表的组合来存储键值对。双向链表维护了插入顺序或访问顺序,保证了迭代顺序与插入顺序或访问顺序一致。
迭代顺序:
HashMap:不关心插入顺序或访问顺序,迭代顺序无法保证。
TreeMap:基于键的自然顺序或自定义比较器的顺序,迭代顺序为升序。
LinkedHashMap:迭代顺序可以选择插入顺序或访问顺序(最近访问的元素放在最后),保证了迭代顺序与插入顺序或访问顺序一致。
性能方面:
HashMap:插入和查找操作的时间复杂度为O(1),但在哈希冲突较多的情况下,插入和查找操作可能会退化到O(n)。
TreeMap:插入和查找操作的时间复杂度为O(log n),自带有排序功能。
LinkedHashMap:插入和查找操作的时间复杂度为O(1),与HashMap类似,但比HashMap略慢。
内存消耗:
HashMap:内存消耗相对较低,不需要额外的空间来维护有序性。
TreeMap:内存消耗较高,每个节点需要存储键、值以及额外的指针和颜色信息。
LinkedHashMap:内存消耗略高于HashMap,因为需要额外的双向链表来维护顺序。
综上所述,LinkedHashMap在功能上结合了HashMap和LinkedList的特点,既可以快速插入和查找,又可以保持插入顺序或访问顺序。然而与HashMap相比,LinkedHashMap在内存消耗方面稍高,并且略慢一些。在选择使用时,要根据具体的需求来进行权衡和选择。
注意when后多个满足条件时, 会只取一个, 不会报错.
select max(case when then)
mybatis@var必须在数据库配置文件的数据库地址url中加上一个属性allowMultiQueries=true
参考: MySQL设置变量以及如何在Mybatis中使用
mysql insert t1(v1, v2, v3) select v1, v2, v3 from t2
中间不要value 或 values
FIELD(str,str1,str2,str3,...)
select * from demo order by field(review_status, 2, 3, 1), 其中review_status为字段名field()后可以跟desc与asc
asc(默认): 按照表顺序(231), 且不存在231中的数据排在前面, 231的数据在最后desc: 按照表降序(132), 且不存在132中的数据排在后面, 132的数据在最前面select field(1, 1, 2, 3, 4, 5) res 结果是1select field((select id from (SELECT * FROM demo where id = 1) tt), 4, 1, 2, 1, 3) res 结果是2(后面多个1是取第一个的索引)select field(1, (select id from (SELECT * FROM demo where id in (1, 2, 3)) tt)) res 运行报错Subquery returns more than 1 row, 表示子查询返回多列, 如果其他地方遇到这种情况需要使用limit 1或关键词any或some等等注意必须用sum才可以使用条件,count不可以, 如果count(*)=0时候type_1_percentage为null
SELECT COUNT(*) AS total_count,
SUM(type = 1) AS type_1_count,
(SUM(type = 1) / COUNT(*)) * 100 AS type_1_percentage
FROM your_table;
pgsql中虽然不支持这样, 但是可以sum(case when type = 1 then 1 else 0), 巧妙引入case when语句来解决
@Conditional运行jar包时候可以指定: java -jar myapp.jar --spring.profiles.active=prod
ConditionalOnExpression
@ConditionalOnExpression("'prod'.equals('${spring.profiles.active}')") 或 @ConditionalOnExpression("${spring.profiles.active.equals('prod')}").@Slf4j
@Configuration
@EnableScheduling
@RequiredArgsConstructor
@ConditionalOnExpression("'prod'.equals('${spring.profiles.active}')")
public class MidJob {
}
@Bean放在一起@RequiredArgsConstructor的onConstructor参数, 如:@RequiredArgsConstructor(onConstructor_ = {@Autowired, @ConditionalOnExpression(...)})Conditionalorg.springframework.context.annotation.Condition.matches()方法, 见下图: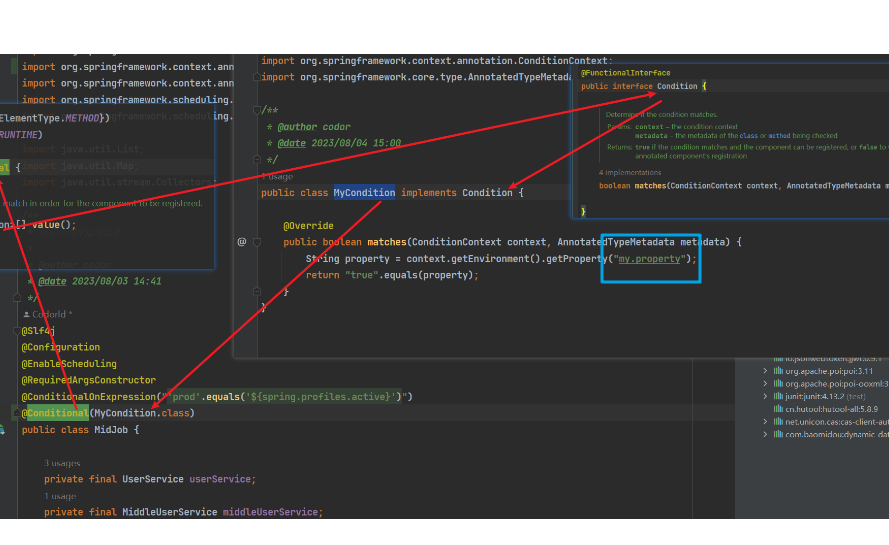
redis.conf中的dir下./, 但是我生成的备份文件在根目录下, 反正根目录, 主目录, redis安装目录结合生成/修改时间检查一下. 恢复服务器那边不清楚的话, 可以执行save指令查看以下生成dump.rdb文件在哪里, 就复制到哪里就行, 建议配置将日志和路径都修改到redis安装目录或者自定义的数据路径中, 防止出现默认./结果出现在根目录下的情况.UPDATE t1
JOIN t2 ON t1.t2_id = t2.id
SET t1.t2_name = t2.name;
UPDATE t1
SET t2_name = t2.name
FROM t2
WHERE t1.t2_id = t2.id;
SELECT pid, query FROM pg_stat_activityshow processlist来找(来源是表information_schema.processlist), 古也可通过SELECT * FROM information_schema.processlist实现命名空间在图形化工具rdm中看到的效果类似文件目录一样, 他将同样前缀(:前的, 大于等于两条数据)的数据以前缀为目录归并起来, 而在使用上就当成一个整体使用即可
(这里提供两个版本下载rdm2021.4, 和rdm2022.5, 老版本稳定, 新版本界面和功能多, 电脑性能不高可能会卡)
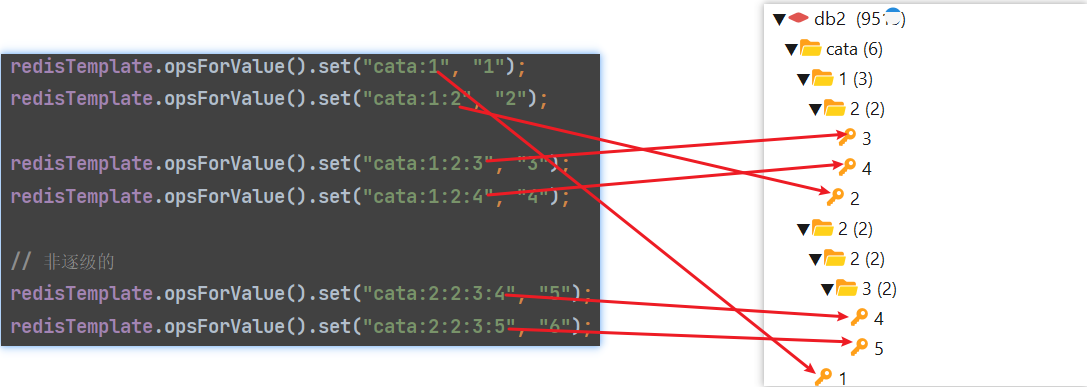
redisTemplate.opsForValue().set("cata:1", "1");
redisTemplate.opsForValue().set("cata:1:2", "2");
redisTemplate.opsForValue().set("cata:1:2:3", "3");
redisTemplate.opsForValue().set("cata:1:2:4", "4");
// 非逐级的
redisTemplate.opsForValue().set("cata:2:2:3:4", "5");
redisTemplate.opsForValue().set("cata:2:2:3:5", "6");
1-java stream peek vs map;; 2-java各种map;; 3-mysql列变行;; 4-java @Conditional;; 5-redis命名空间;; 等等等等...
算法学习笔记,记录容易忘记的知识点和难题。详解时空复杂度、50道常见面试笔试题,包括数组、单链表、栈、队列、字符串、哈希表、二叉树、递归、迭代、分治类型题目,均带思路与C++题解