import os
from pyquery import PyQuery as pq
# 1. 配置爬取信息: 待爬取网站、小说的url、小说名字
website = 'https://www.bbiquge.net'
novel_url = '/book/133312/'
novel_name = '宇宙职业选手'
# 2. 解析网页
novel_init_page = pq(url=website+novel_url)
# 3. 每本小说底部的页数
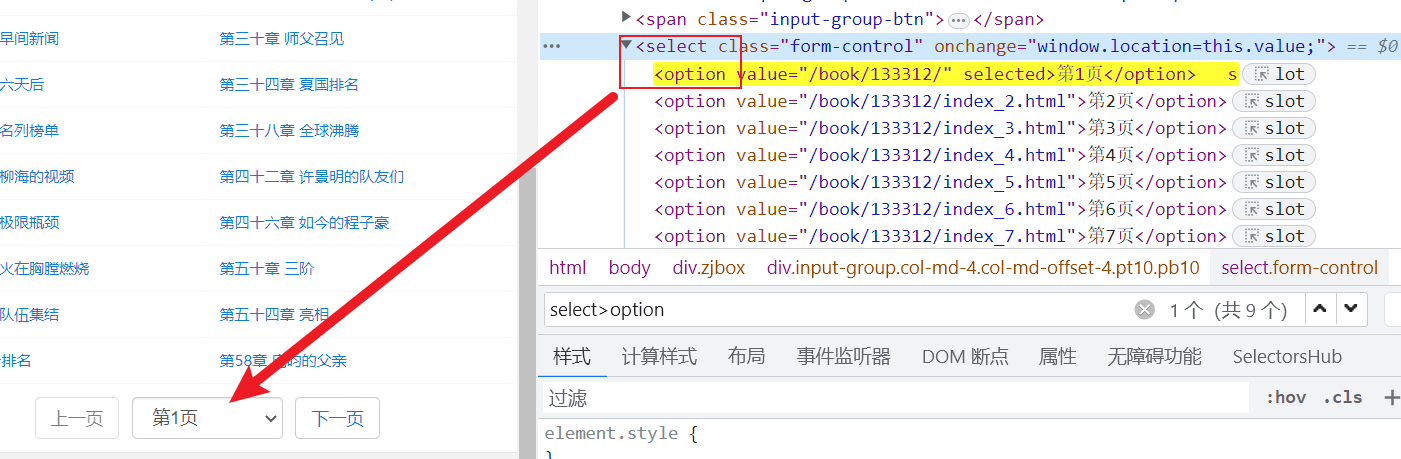
pages = novel_init_page('select>option').items()
# 4. 写入<小说名>.md文件
with open(f'{novel_name}.md','w',encoding='utf-8') as f:
# 4.1 遍历页数
for page in pages:
# 4.1.1 获取每一页的URL
individual_page_url = website+page.attr.value
# 4.1.2 解析每一页
page_info = pq(url=individual_page_url)
# 4.1.3 得到每个小说章节的信息,如 “第一章 XXXXX”
chapters = page_info('.zjlist>dd>a').items()
# 4.1.4 遍历每个章节
for chapter in chapters:
# 垃圾章节过滤
if '获奖公布' in chapter.text():
continue
# 以MD形式写入章节名,记得换行
f.write('# '+chapter.text()+'\n')
# 注意此处的拼接URL,不能是individual_page_url,每个章节正文的内容是website+novel_url下的
chapter_url = website+novel_url+chapter.attr.href
# 解析正文的URL
chapter_info = pq(url=chapter_url)
# 垃圾信息清理
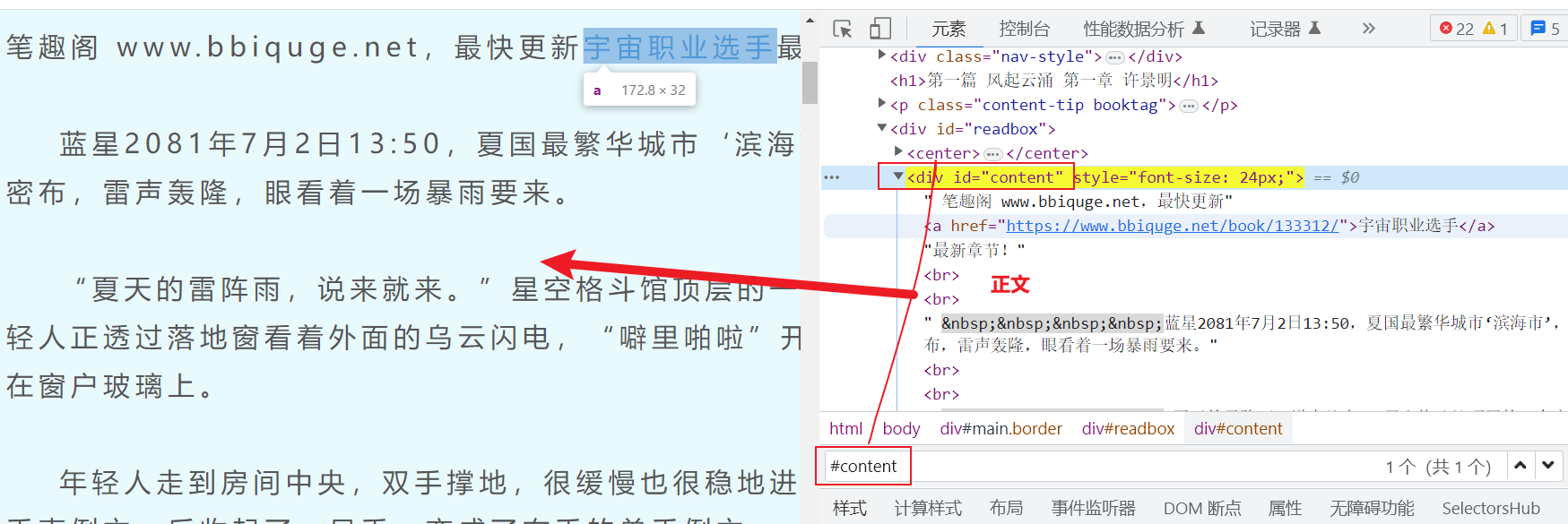
open_info = f'笔趣阁 www.bbiquge.net,最快更新{novel_name}最新章节!'
chapter_content = chapter_info('#content').text().replace(open_info,'')
f.write(chapter_content+'\n')
# 5. 当文档超过1024KB的时候最好分割下,不然md可能无法直接打开,你可以用txt工具打开
# fsplit需要单独安装 参考: https://github.com/dubasdey/File-Splitter
os.system(f'fsplit -split 1024 kb ./{novel_name}.md -df ./')
解释都在代码里
你要执行可能要去掉最后一行,否则就自行下载好fsplit
本代码仅适用于特定的网站(https://www.bbiquge.net),并不推荐盗版,仅供学习之用
如果要下载特定网站的其他小说,可以修改novel_url,novel_name最好也同步
再改改,就可以爬取该特定网站所有的小说
元素表达式说明:第几页==>select>option,如图