re库。正则表达式是用来进行字符串匹配的一个字符形式。
常见的正则表达式测试工具有:
?
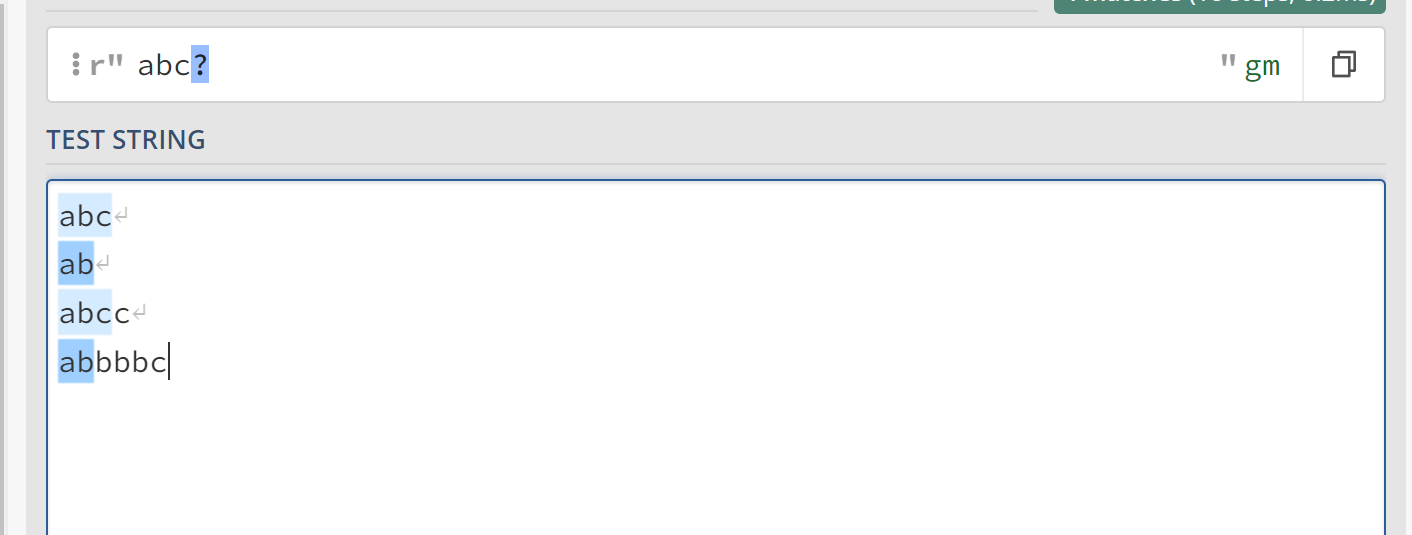
abc?表示字符c需要出现0次或者1次,或者换句话说,字符c至多出现一次。也就是说,abc?相当于abc和ab这两个字符串。
*
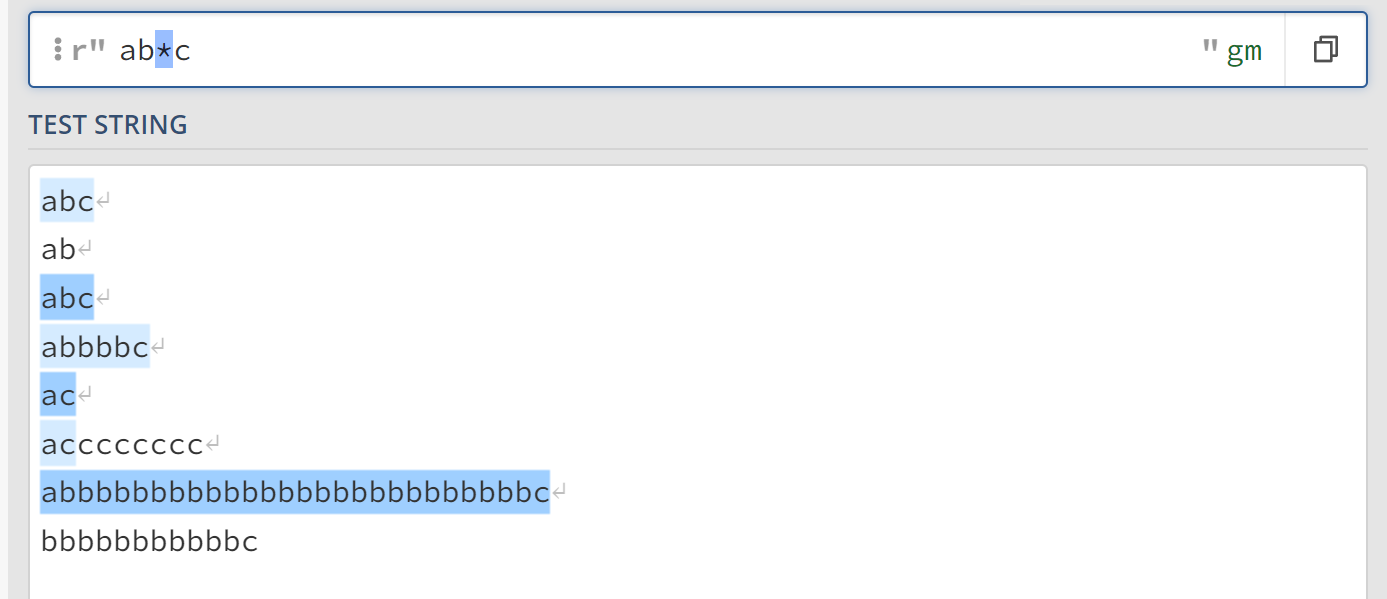
ab*c表示字符b需要出现0次或者多次,或者换句话说,字符b可以出现任意多次。也就是说,ab*c相当于ac、abc、abbc、ab……bc等多个字符串。
+
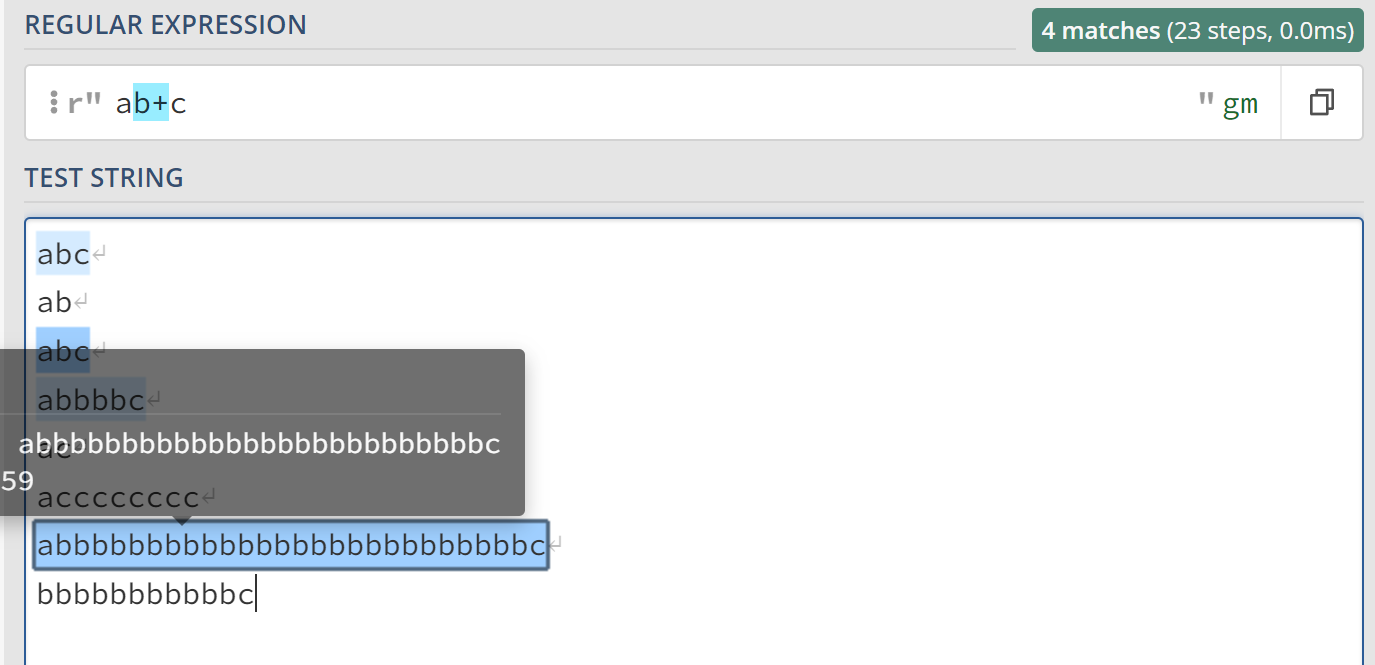
ab+c表示字符b需要出现1次或者多次,或者换句话说,字符b至少出现一次。也就是说,ab+c相当于abc、abbc、ab……bc等多个字符串。
注意ab*c和ab+c的细微区别。
{}
{num}
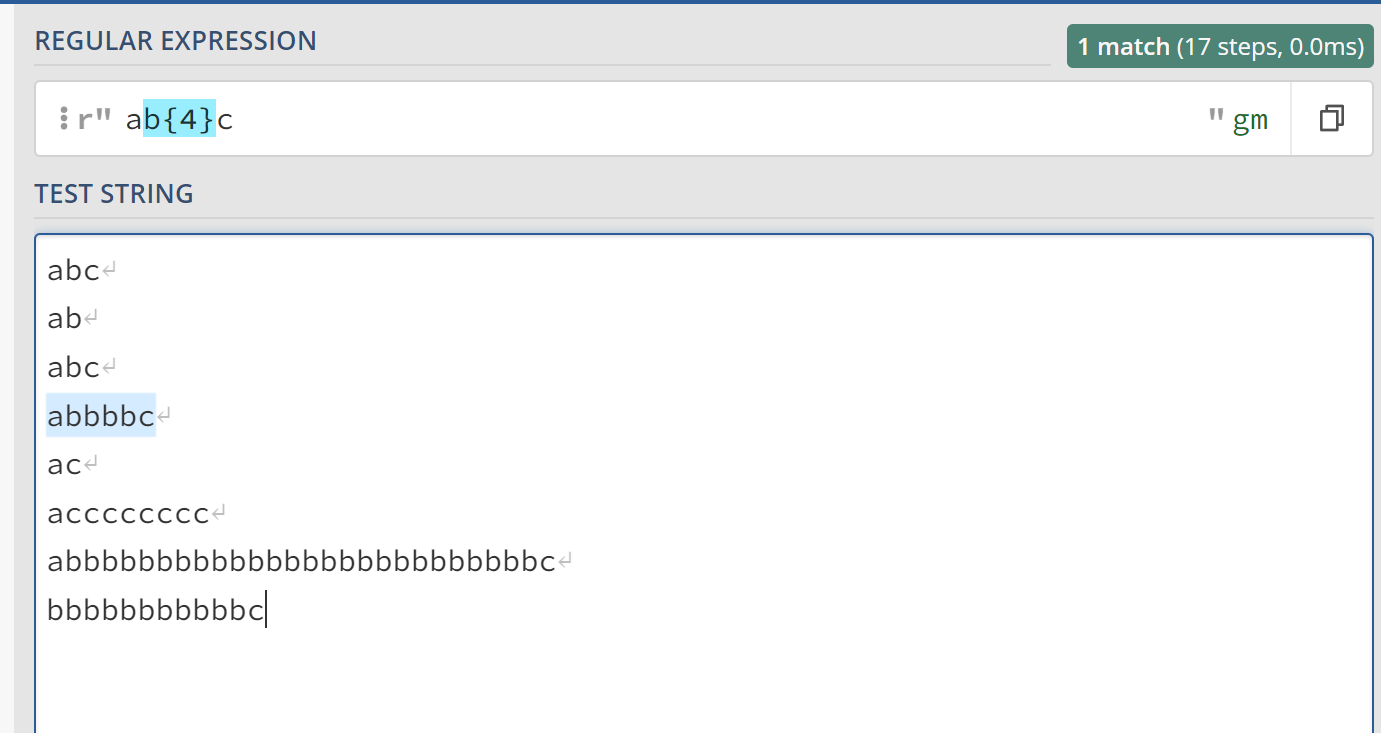
ab{3}c表示字符b需要出现3次,或者换句话说,字符b只能出现2次。也就是说,ab{2}c相当于abbc这一个字符串。
{num1,num2}
ab{2,5}c表示字符b需要出现2或3或4或5次,也就是说,ab{2,5}c相当于abbc、abbbc、abbbbc、abbbbbc这四个字符串。
{num,}
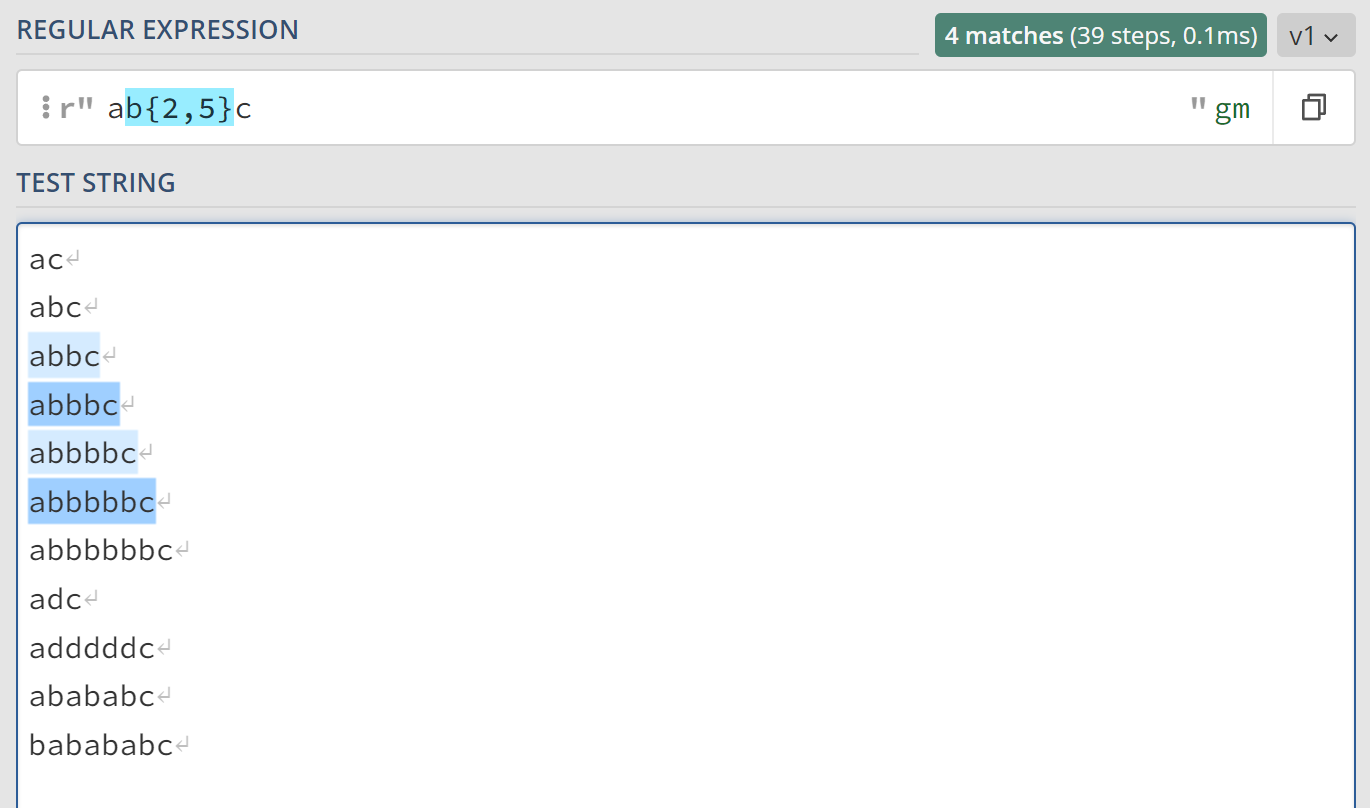
ab{2,}c表示字符b需要出现2次及以上,也就说,ab{2,}c相当于abbc、abbbc、abbbbc、ab……bc等无数个字符串。
在正常情况下,上述的限定符只会对其前面的一个字符起作用。如果想要某个字符串作为一个组合,可以使用字符集。
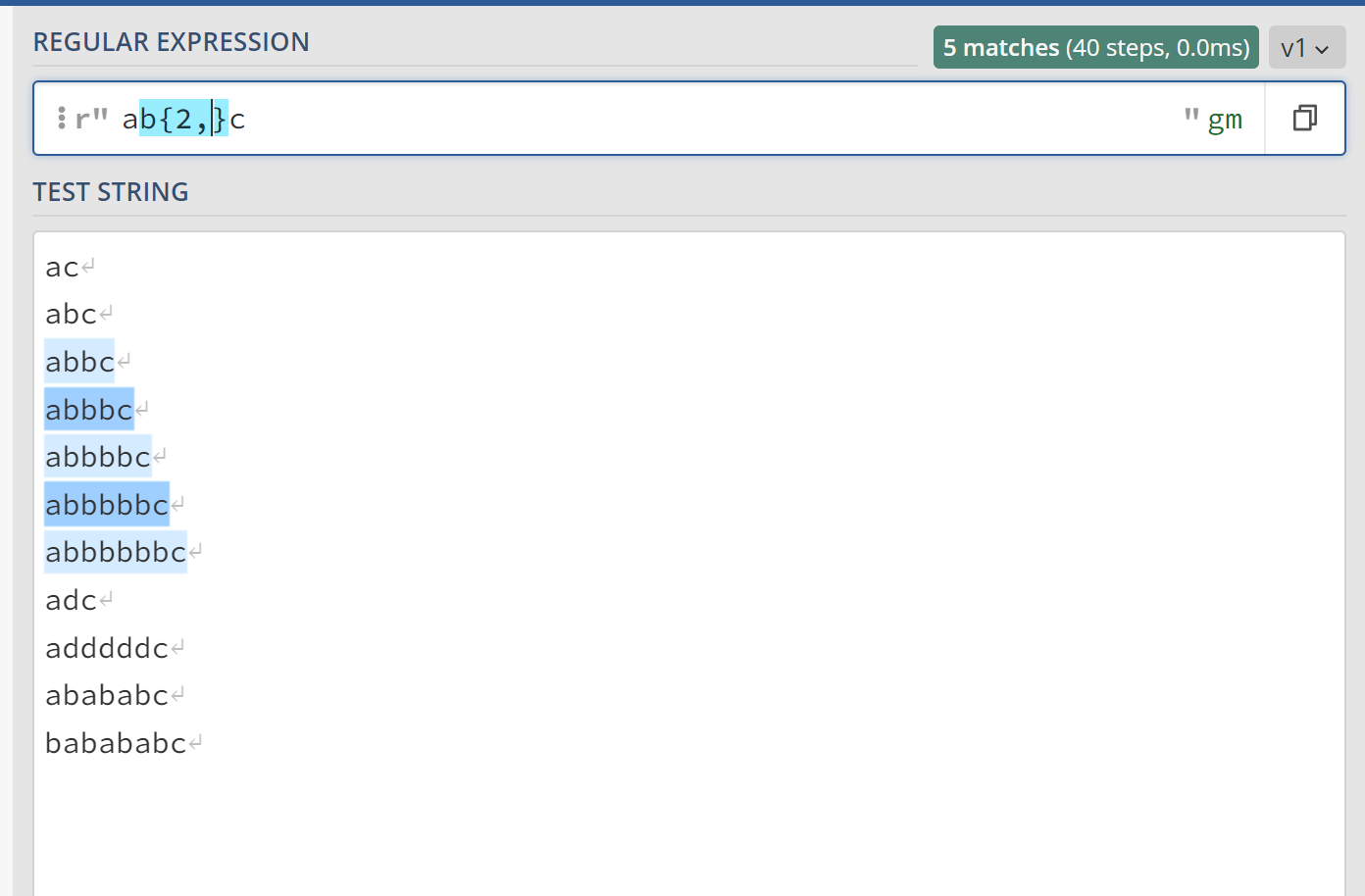
(ab)+c表示字符串ab需要出现1次或者多次,或者换句话说,字符串ab至少出现一次。也就是说,(ab)+c相当于abc、ababc、abababc、ab……abc等多个字符串。
|
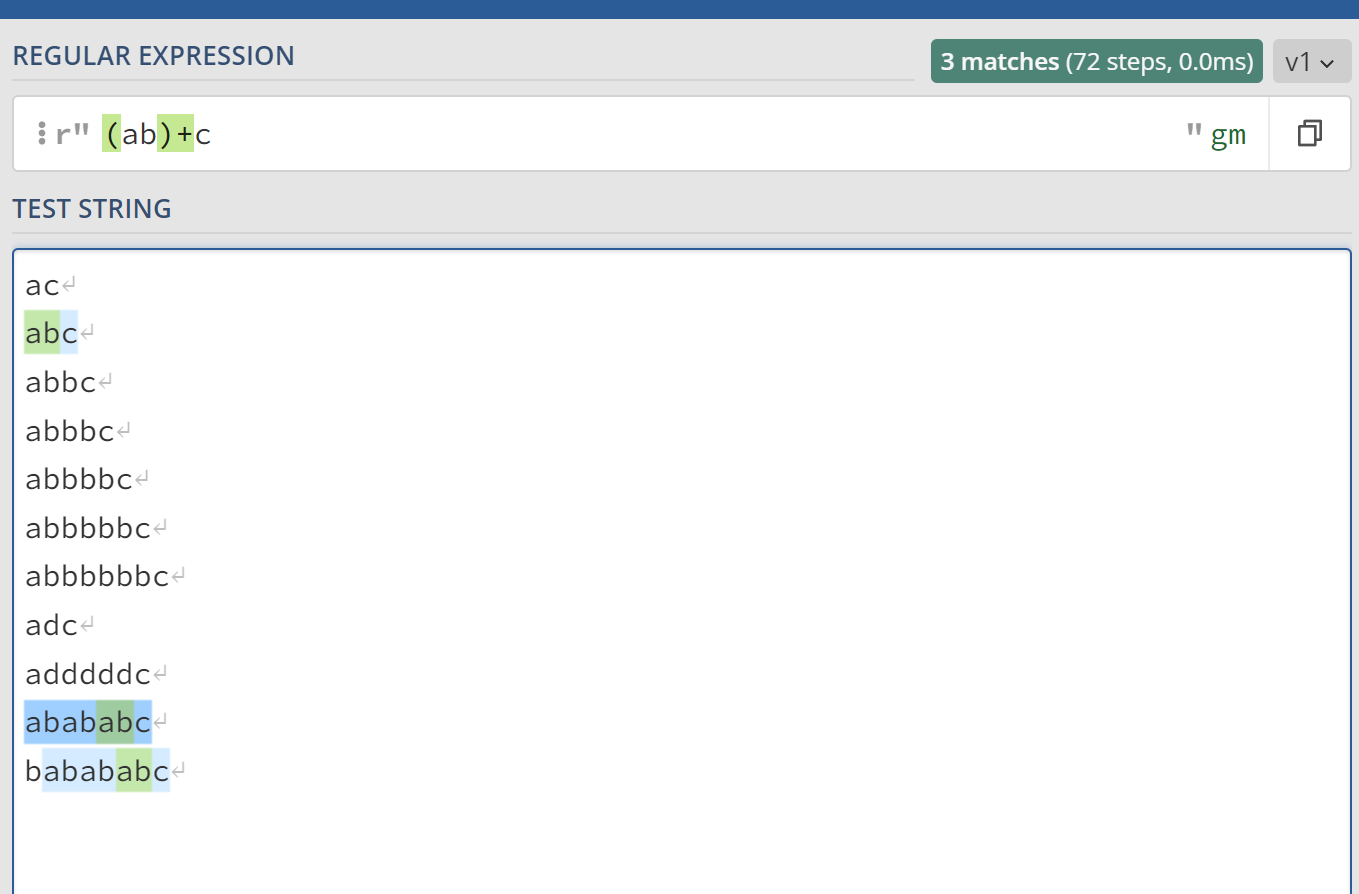
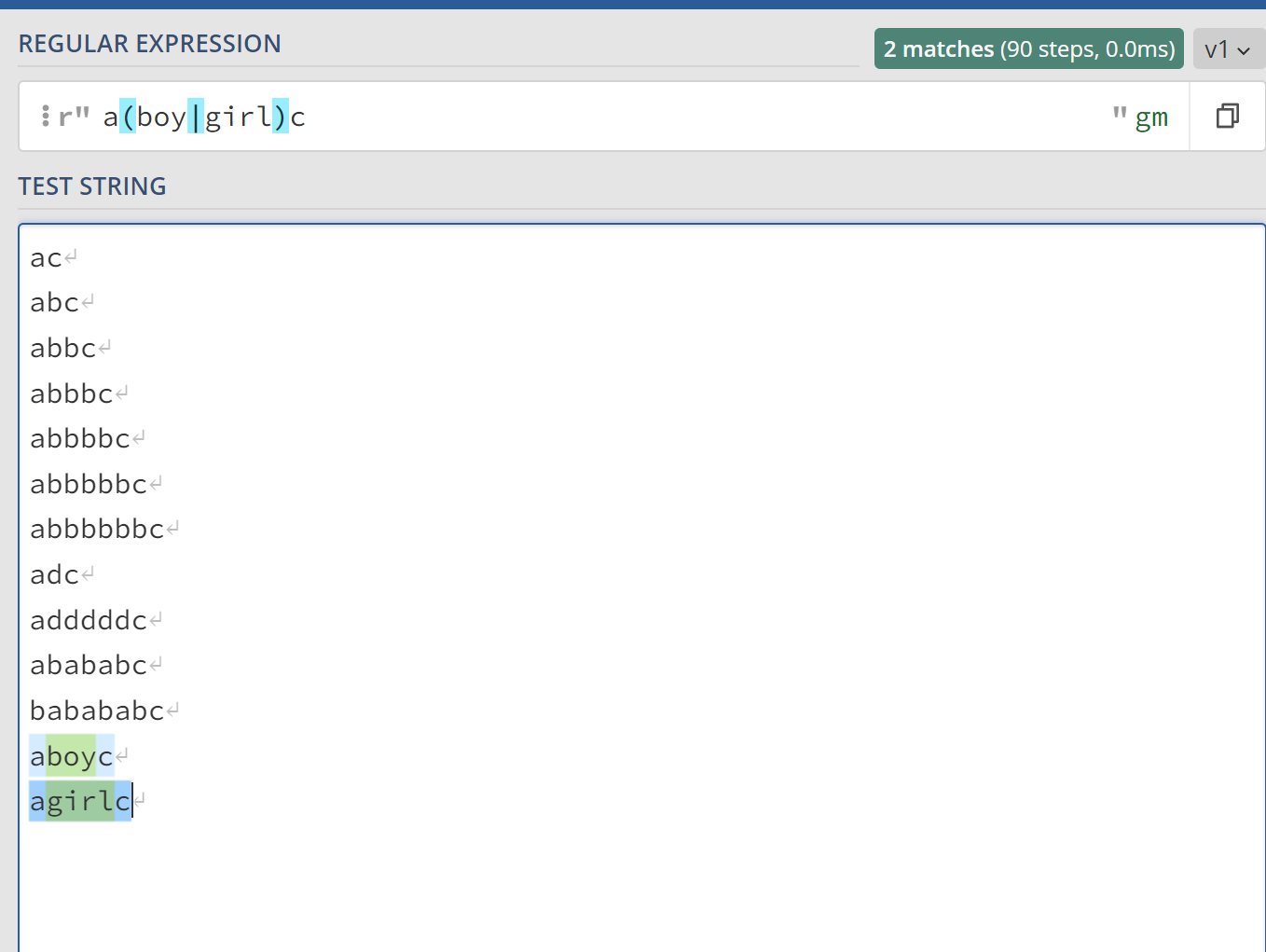
a(b|d)c表示字符串b出现1次或者字符串d出现1次,也就是说,a(b|d)c相当于abc、adc这两个字符串。
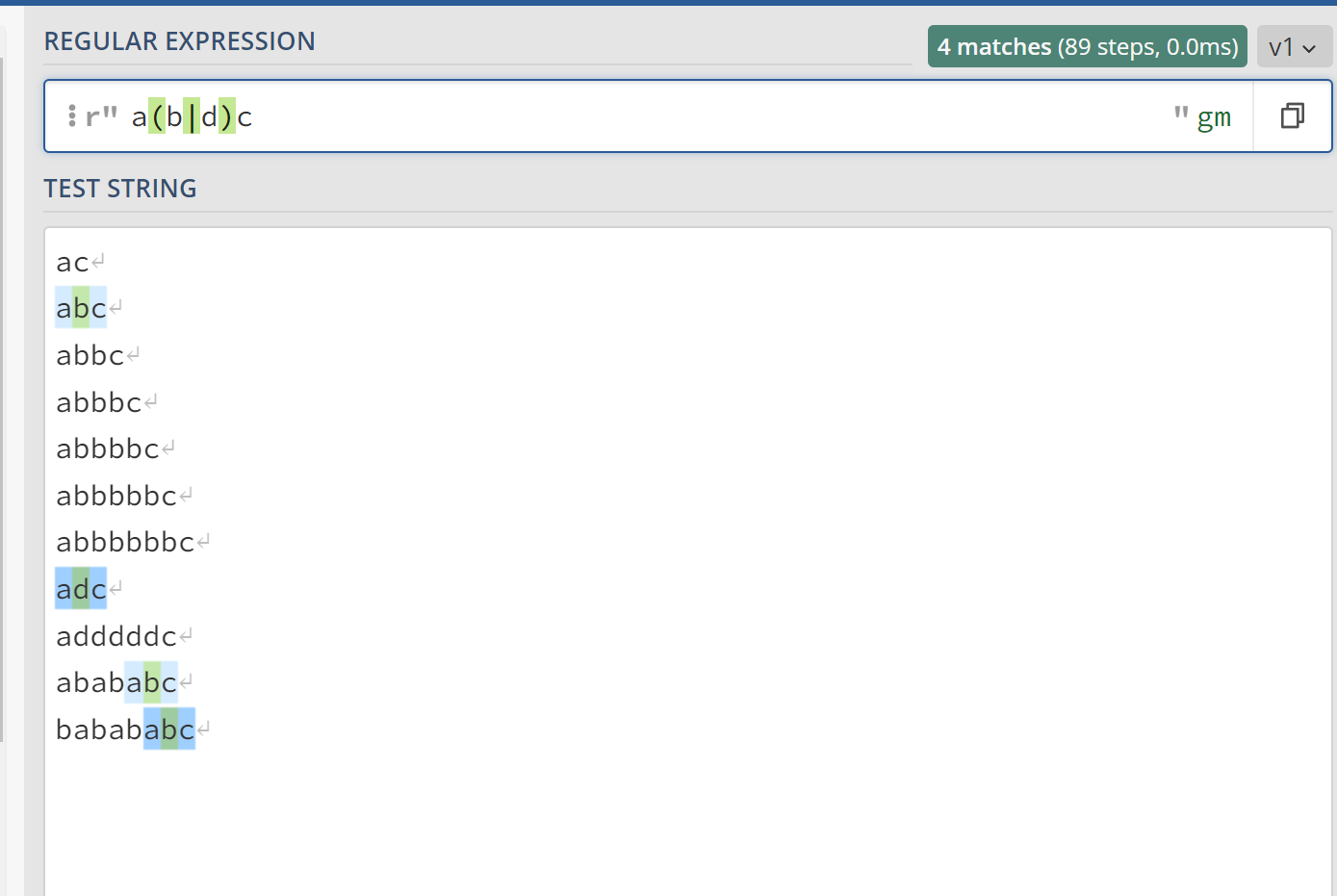
a(boy|girl)c也同样适用,相当于aboyc或者agirlc这两个字符。
[]
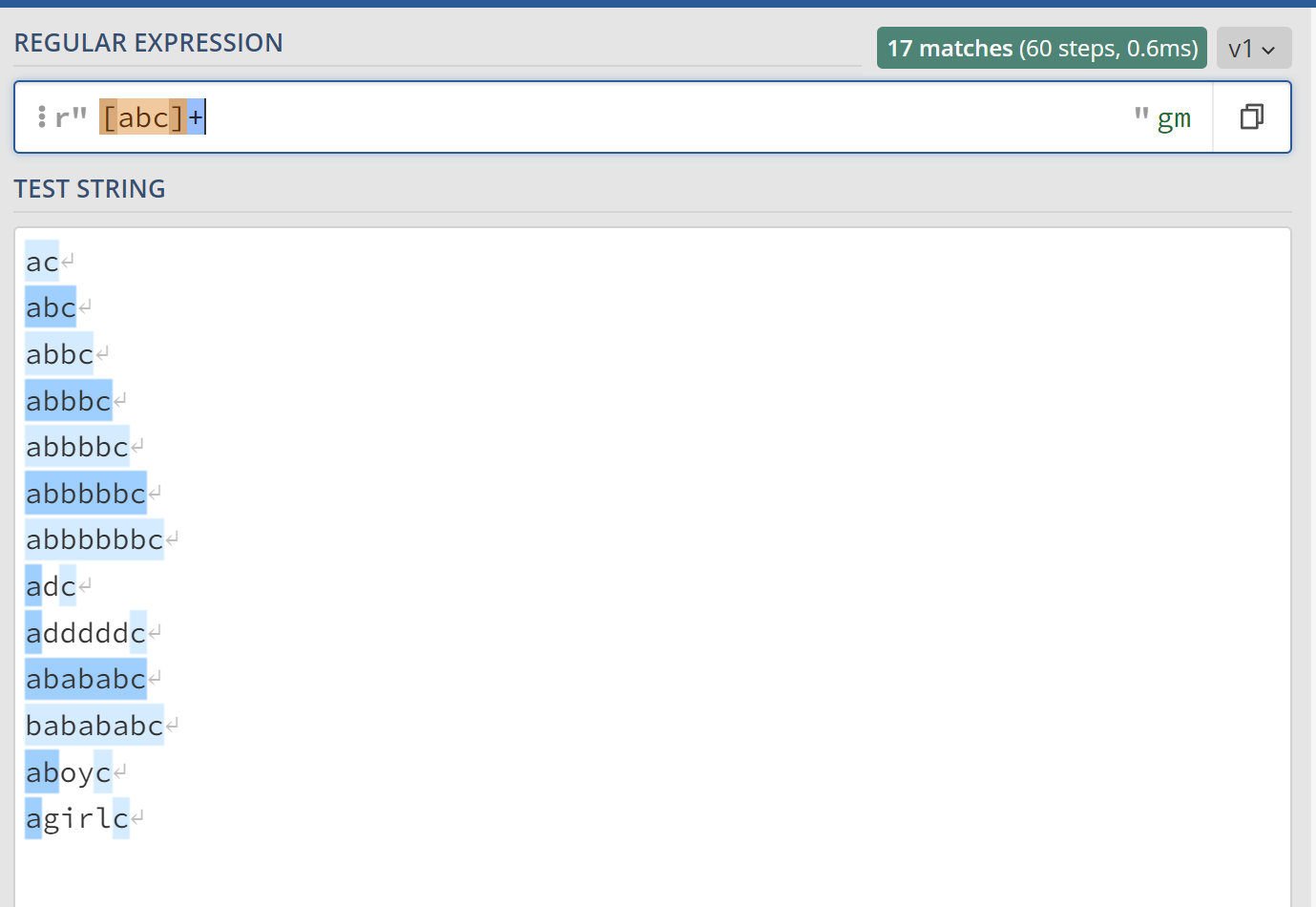
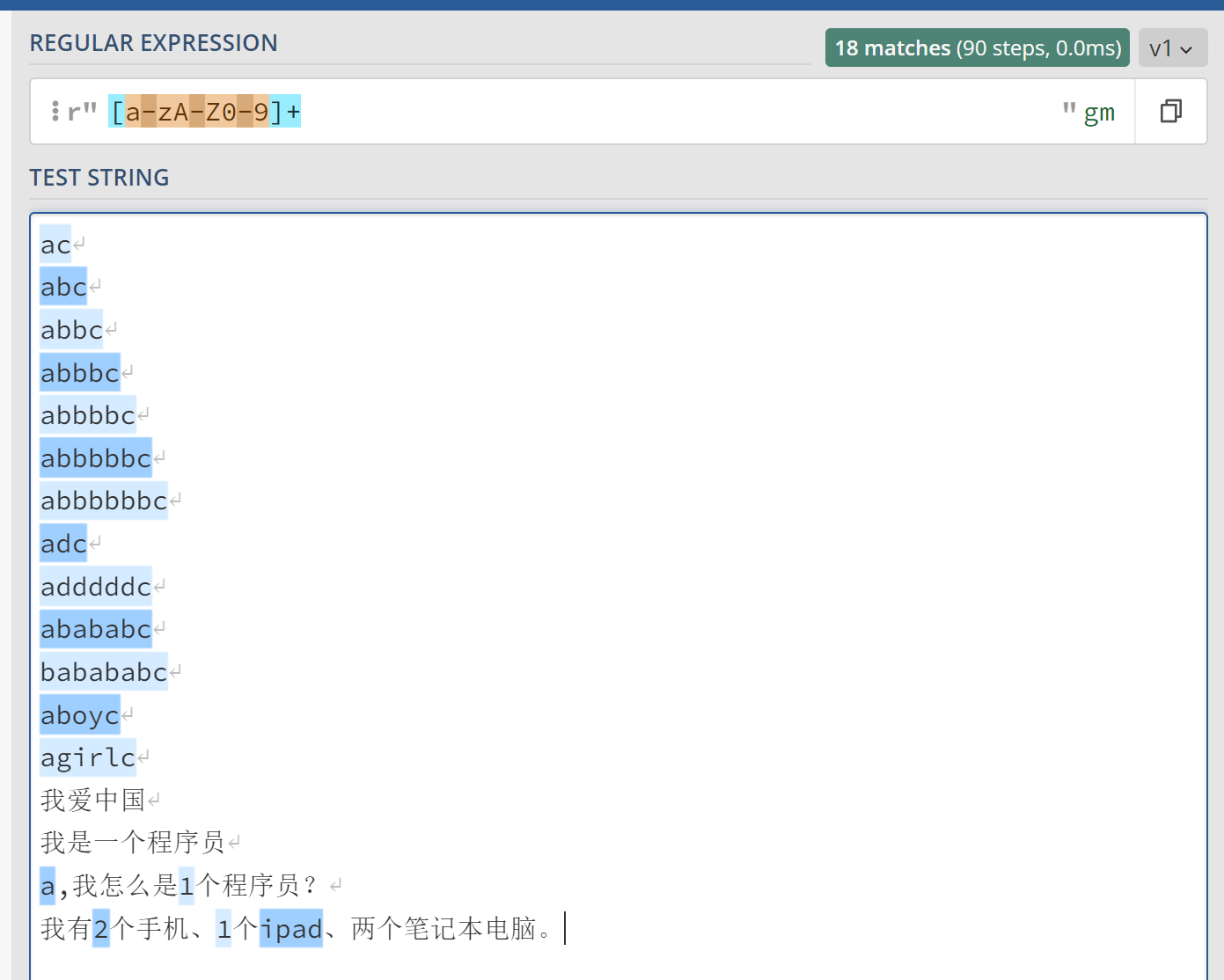
[]表示匹配字符能选择的范围,成为字符类,例如,[abc]+只会匹配a\b\c这三个字母出现一次或多次的字符串,而一般更经常使用的是[a-zA-Z0-9]*表示由大小写字母和数字组成的字符串,[a-zA-Z0-9_]*表示由大小写字母、数字和下划线组成的字符串。
^
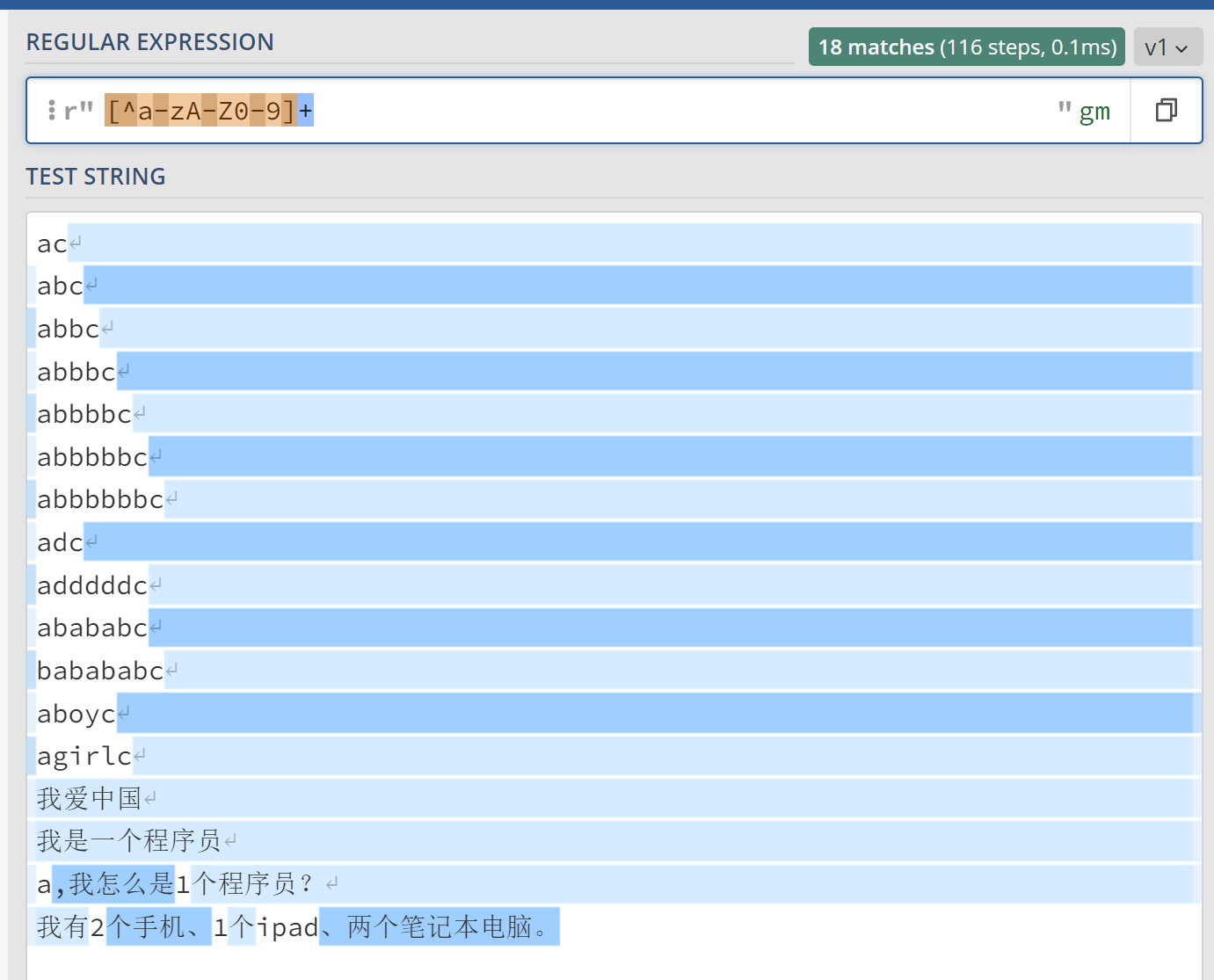
^表示取反字符类,也就是说,[^a-zA-Z0-9]*表示除了大小写字母、数字符号以外的其他字符出现一次或多次的字符串。
\
\.表示转置,把一些有特殊意义的字符转变为实际字符
\b
\b表示字符边界
\d数字字符
\D非数字字符\w单词字符,包括英文字母、数字、下划线
\W非单词字符\s空白字符,包括空格、制表符、换行符
\S非空白字符.任意字符,不包含换行符^匹配字符串的开头,例如^a匹配行首的a$匹配字符串的结尾,例如x$匹配行尾的x<.+>匹配<和>之间的任意字符,而<.+?>则会使用懒惰匹配