
GitHub 上开源的字体不在少数,但是支持汉字以及其他非英文语言的字体少之又少,记得上一个字体还是 霞鹜文楷,本周 B 站知名设计 UP 主开源了的得意黑体在人文观感和几何特征之间找到了美的平衡。
而文本编辑器剪视频 autocut 则优雅和便捷之间找到它的平衡,分布式时序数据库 greptimedb 灵活地周旋于强分析力和高性能,LaTeX 生成器 latexify_py 两手抓住 Python 源码和 AST。
以下内容摘录自微博@HelloGitHub 的 GitHub Trending 及 Hacker News 热帖(简称 HN 热帖),选项标准:新发布 | 实用 | 有趣,根据项目 release 时间分类,发布时间不超过 14 day 的项目会标注 New,无该标志则说明项目 release 超过半月。由于本文篇幅有限,还有部分项目未能在本文展示,望周知 🌝
主语言:Python
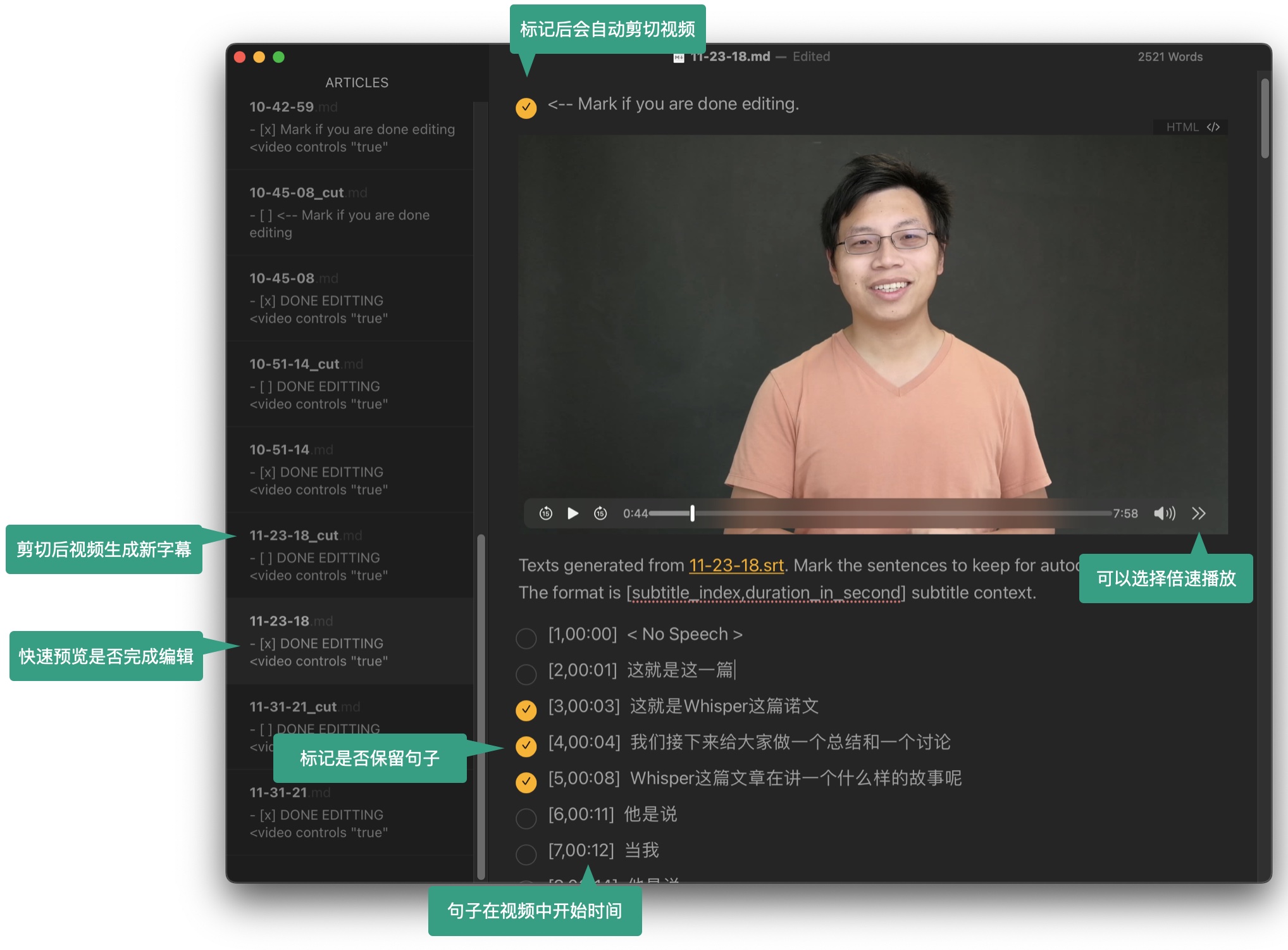
New AutoCut 会对你的视频自动生成字幕,再选择所需保留的句子,AutoCut 便会对视频中相应的片段裁切并保存。无需使用视频编辑软件,只需要编辑文本文件即可完成剪切。
GitHub 地址→https://github.com/mli/autocut
主语言:HTML
New 得意黑是一款在人文观感和几何特征中寻找平衡的中文黑体。整体字身窄而斜,细节融入了取法手绘美术字的特殊造型。字体支持简体中文常用字(覆盖 GB2312 编码字符集)、拉丁字母、日文假名、阿拉伯数字和各类标点符号。
目前 smiley-sans 除了支持常见数字和标点外,还支持汉字(6,767 个)、拉丁字母(覆盖欧洲、美洲、南亚各种语言所需的字符共 415 个)以及日文假名(174 个)。

本周 star 增长数:1,300+,主语言:Python
New GALACTICA 是一个通用语言模型,经过大量的科学文本和数据的训练,它能高效地完成学术上的 NLP 任务,尤其是在引用预测、数学推理、生物、医学上有出色的性能。通过下列方式即可快速用上该模型:
import galai as gal
model = gal.load_model("standard")
model.generate("Scaled dot product attention:\n\n\\[")
# Scaled dot product attention:\n\n\\[ \\displaystyle\\text{Attention}(Q,K,V)=\\text{softmax}(\\frac{QK^{T}}{\\sqrt{d_{k}}}%\n)V \\]
复制GitHub 地址→https://github.com/paperswithcode/galai
本周 star 增长数:1,350+,主语言:Rust
New GreptimeDB 是一个开源的时序数据库,专注于可扩展性、分析力和效率。一些特性:

本周 star 增长数:1,350+,主语言:CSS
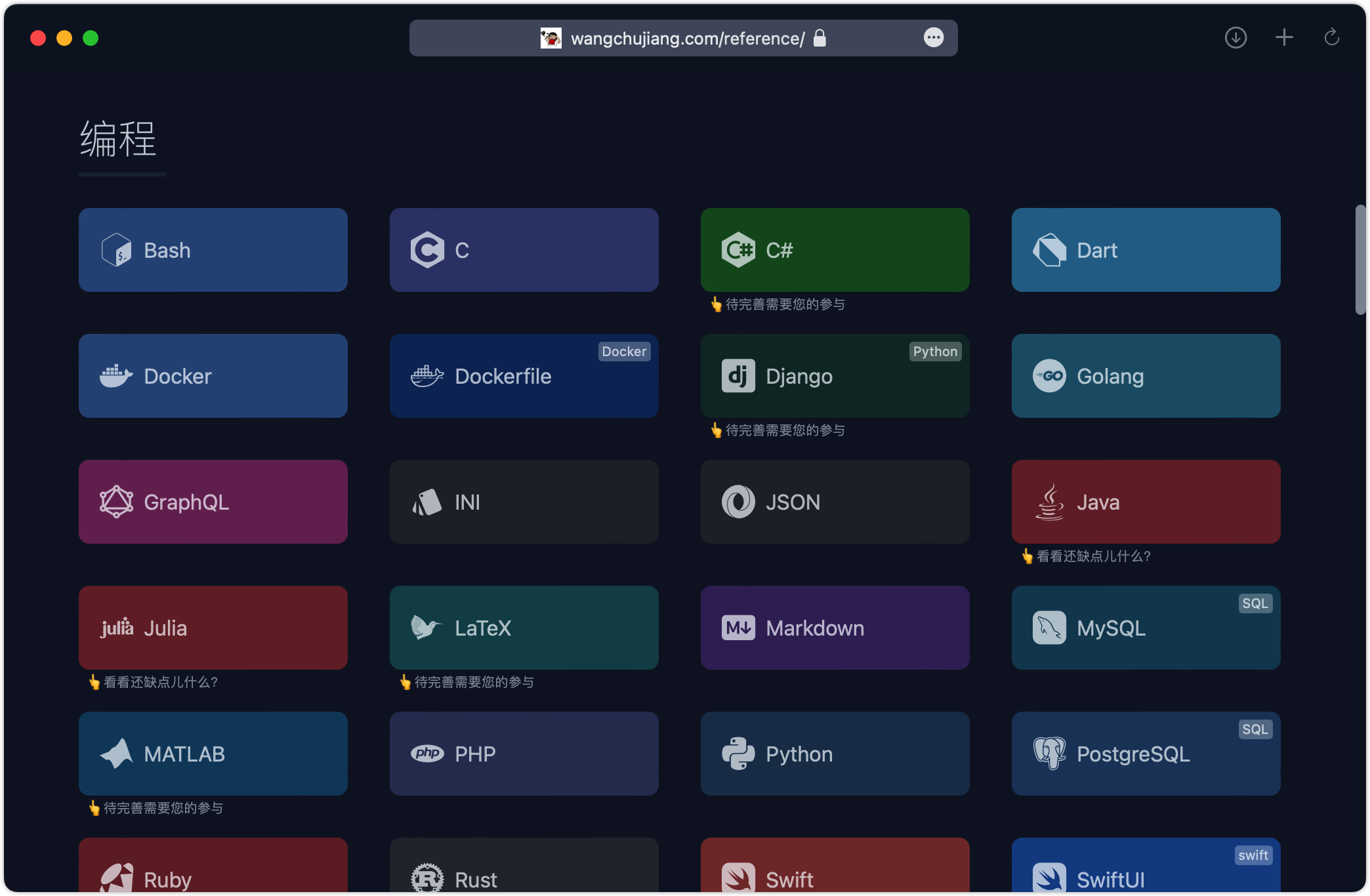
New 可快速根据你的技术栈快速找寻相关知识,从入门到进阶的 Tips 都有。reference 英文可查阅链接:https://github.com/Fechin/reference。
GitHub 地址→https://github.com/jaywcjlove/reference
本周 star 增长数:700+,主语言:Python
latexify 是一个 Python 包,用来编译一段 Python 代码为 LaTeX。它主要提供以下两个功能:
GitHub 地址→https://github.com/google/latexify_py

本周 star 增长数:900+,主语言:Golang
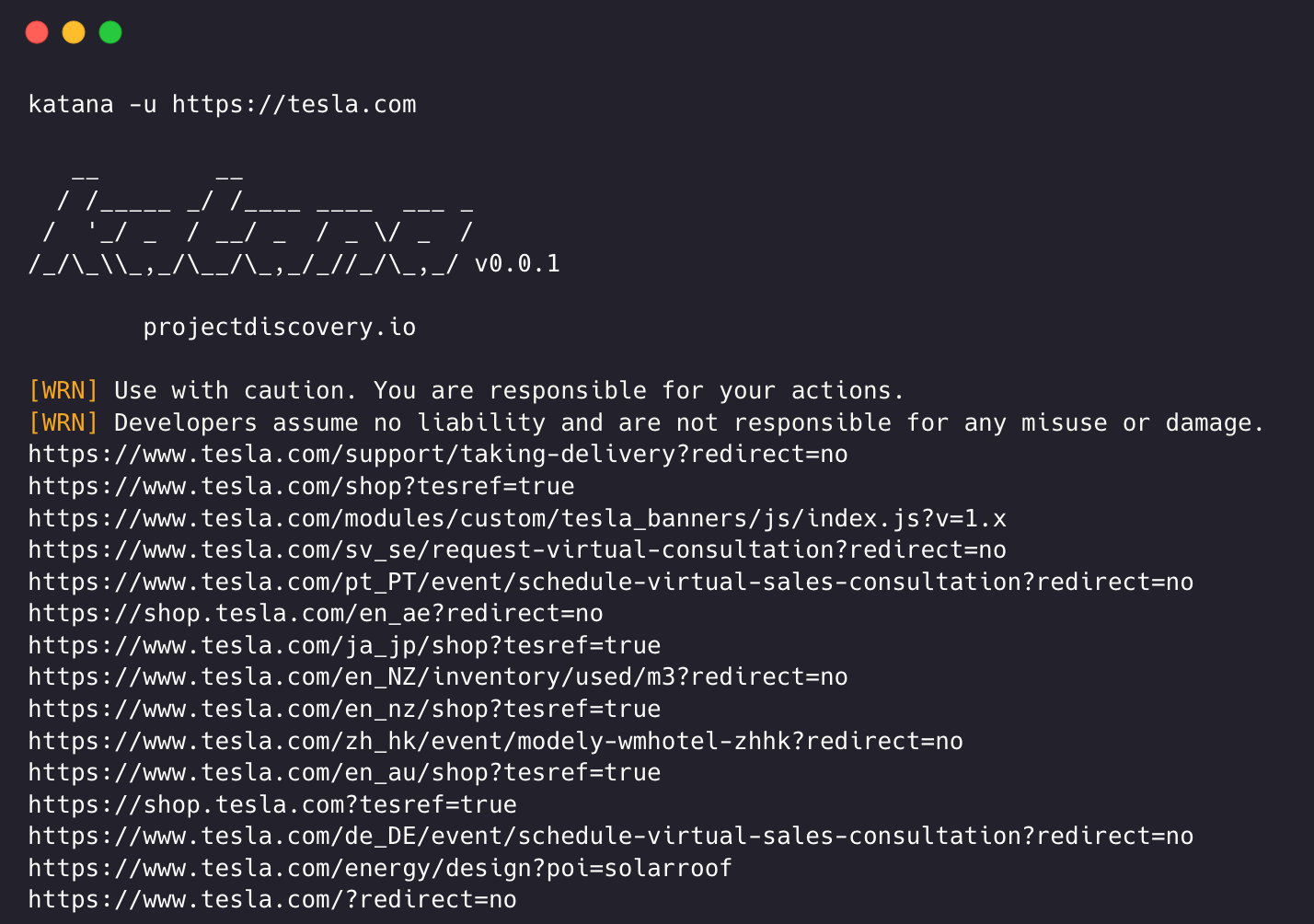
New 作为下一代爬虫框架,katana 有以下特性:
往期回顾:
以上为 2022 年第 46 个工作周的 GitHub Trending 🎉如果你 Pick 其他好玩、实用的 GitHub 项目,记得来 HelloGitHub issue 区和我们分享下哟 🌝
最后,记得你在本文留言区留下你想看的主题 Repo(限公众号),例如:AI 换头。👀 和之前的送书活动类似,留言点赞 Top3 的小伙伴(棒),小鱼干会努力去找 Repo 的^^
HelloGitHub 交流群现已全面开放,添加微信号:HelloGitHub001 为好友入群,可同前端、Java、Go 等各界大佬谈笑风生、切磋技术~