
在大数据和 AI 的时代背景下,数据已经成为了重要财富,大到政务数据、企业核心数据,小到个人信息、银行卡余额,这些数据无一例外都是“隐私数据”,如果在使用和流转时发生泄漏都会造成巨大的损失。
那有没有什么方法,可以在不暴露数据隐私的前提下,让数据流动起来发挥更大的价值呢?在这个问题的驱使下我们找到了今天的主角——隐私计算。
隐私计算是指在不泄露数据本身的情况下,实现数据分析和计算的技术,具有“数据可用不可见”的特点,让数据安全合规地流动起来。
下面用一个经典的百万富翁问题,来帮助理解什么是“数据可用不见”。

假设有两个百万富翁,他们都想知道谁更富有,但又不想让对方或者第三方,知道自己具体有多少钱。
按照常理,进行比大小的计算是需要知道两个数是多少,才能比较大小,但这里不知道具体的数字。所以上面这个问题在普通人看来是无解的,但其实这是一个密码学问题,也被称为“多方安全计算”(MPC)问题,由姚期智院士在 1982 提出,并给出了解决方案——混淆电路,实现了数据的可用不可见。
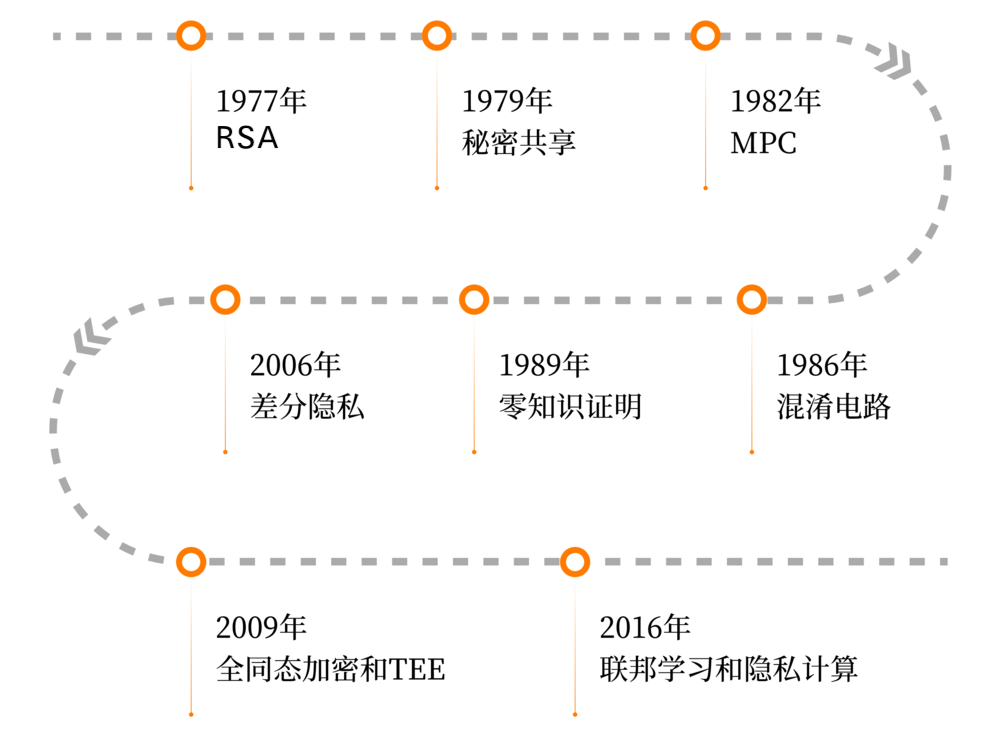
从隐私计算的技术发展时间线,我们不难看出隐私计算还是一个比较“新”的技术。随着零知识证明、差分隐私、全同态加密、联邦学习等技术的相继问世,目前已形成三大应用技术路线多方安全计算(MPC)、联邦学习(FL)、可信执行环境(TEE),隐私计算作为数据流通的重要技术已应用于金融、医疗、政务、广告等领域。
随着欧盟 2018 年生效的《通用数据保护法案》,Google、Facebook 等科技巨头都收到了巨额罚单。近两年,我国也相继出台了 《数据安全法》 和 《个人信息保护法》。因此,如何让数据安全地流通起来,已经不再是一道附加题而是一道必答题。
如果我们把上面的“百万富翁”换成企业/机构的话,就可以很容易得出隐私计算技术就是数据安全流通的答案 🔑。
那么,对于没有隐私计算技术背景的程序员、或是没有相关研发团队的企业/机构,如何才能快速用上隐私计算技术,让数据流通起来创造更大的价值呢?

今天,HelloGitHub 给大家带来一款由密码学专家团队打造的开源隐私计算平台——PrimiHub,它开箱即用、支持 CLI 和可视化 Web 界面,让你无需具备隐私计算技术背景,就能上手发起隐私计算任务。
GitHub 地址:https://github.com/primihub/primihub
下面,我将先介绍如何快速上手 PrimiHub,最后通过演示一个完整的应用案例,让你能够真正的入门 PrimiHub,并将隐私计算应用到实际的业务中。
PrimiHub 是在隐私计算应用技术之上构建的隐私计算平台,封装了底层的密码学协议让开发者专注于业务、更容易上手。下面就让我们实际上手体验一下,让数据流动起来吧!
虽然 PrimiHub 提供了 Docker、可执行文件、本地编译的安装方式,但是如果你只是想在本地体验一下,我强烈推荐 Docker 一键安装,因为真的是太 easy 了 ~
# 第一步:下载
git clone https://github.com/primihub/primihub.git
# 第二步:进入目录
cd primihub
# 第三步:启动
docker-compose up -d
复制PrimiHub 将复杂的隐私计算技术封装成了一个个任务,只需要修改配置文件,然后执行命令发起任务即可。
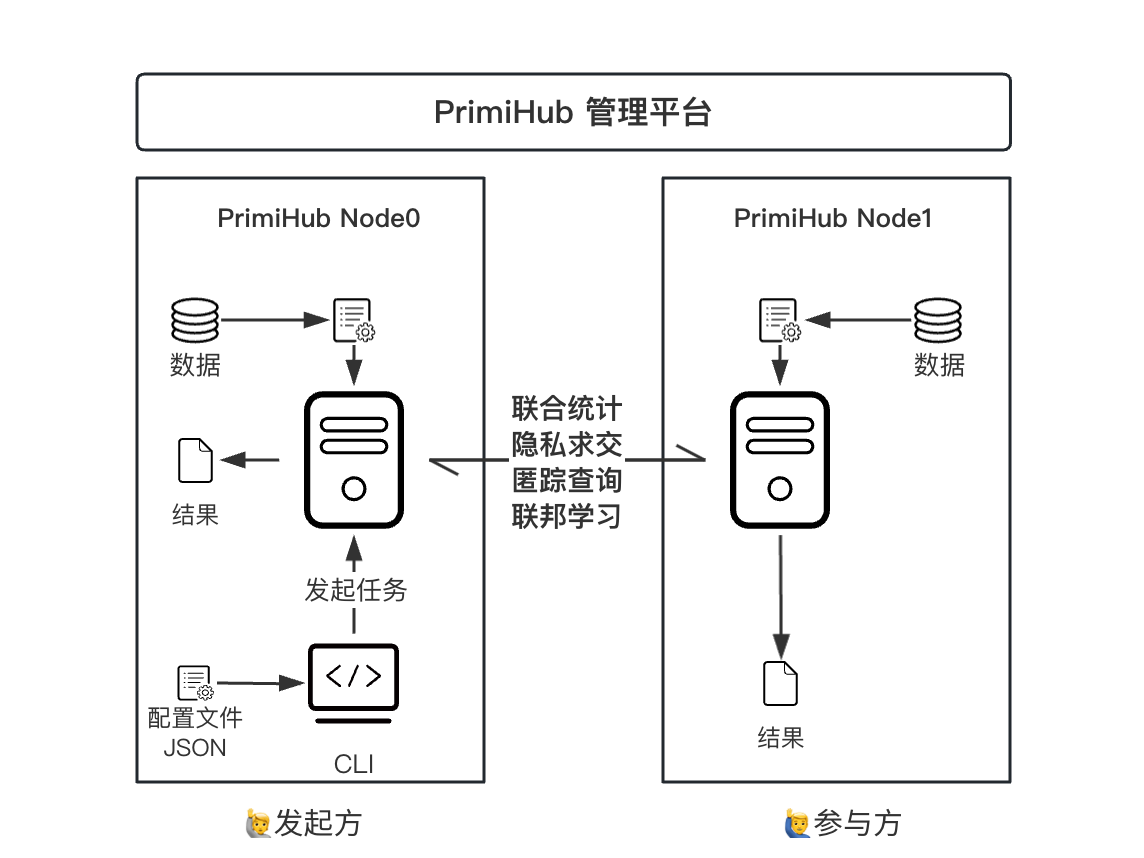
PrimiHub 目前支持联合统计、隐私求交、匿踪查询、联邦学习等功能。
下面是通过命令行发起一个「隐私求交」任务的全过程,task_config_file 参数指定配置文件。
# 1. 进入容器
docker exec -it primihub-node0 bash
# 2. 发起隐私求交任务
./primihub-cli --task_config_file="example/psi_ecdh_task_conf.json"
I20230616 13:40:10.683375 28 cli.cc:524] all node has finished
I20230616 13:40:10.683745 28 cli.cc:598] SubmitTask time cost(ms): 1419
# 3. 查看结果
cat data/result/psi_result.csv
"intersection_row"
X3
...
复制为了方便用户上手,PrimiHub 在 example 目录下,提供了 50 多种隐私计算任务的配置文件,可作为模板快速配置自己的数据源发起任务。
| 文件 | 任务 |
|---|---|
| mpc_statistics_sum_task_conf.json | 联合统计三方求和(SUM)任务 |
| psi_ecdh_task_conf.json | 隐私求交求两个集合的交集 |
| keyword_pir_task_conf.json | 匿踪查询 |
| hfl_plaintext.json | 线性回归横向联邦明文模式训练 |
| hfl_paillier.json | 线性回归横向联邦同态模式训练 |
| ...... | 更多配置示例 |
这里我们将通过在 PrimiHub 管理平台模拟演示一个匿踪查询(隐匿查询)的应用案例:检察院要向公安机关查询张三(身份证号)是否有涉毒记录,但是公安机关不想把全量数据提供给检察院查询,检察院也不想暴露他们当前正在侦查的对象。
上面的场景,双方可以通过 PrimiHub 的隐匿查询功能来满足双方需求,实现公安机关看不到检察院的查询,检察院也不用拿到公安机关的全量数据,下面开始操作。
匿踪查询需要两方以上进行协同,所以需要选择「节点 1:模拟检察院」和「节点 2:模拟公安机关」进行注册。
节点 1:https://node1.primihub.com/#/register
节点 2:https://node2.primihub.com/#/register
注册完成后打开两个网页分别登陆,刚模拟注册的检察院和公安机关的账号。
本地准备好待查询的数据如下表,以及查询条件身份证号:110221xxxxx
| 姓名 | 身份证号 | 籍贯 | 出生日期 | 涉赌时间 |
|---|---|---|---|---|
| 张三 | 110221xxxxx | 北京市 | ... | ... |
| 李四 | 1102211xxxx | 北京市 | ... | ... |
| 王二 | 11022119xxx | 北京市 | ... | ... |
打开「节点 2」网页(公安机关账号)在「我的资源」点击「添加资源」按钮,将上面表格作为数据资源上传(实际场景中可通过配置数据库进行查询),最后点击保存。
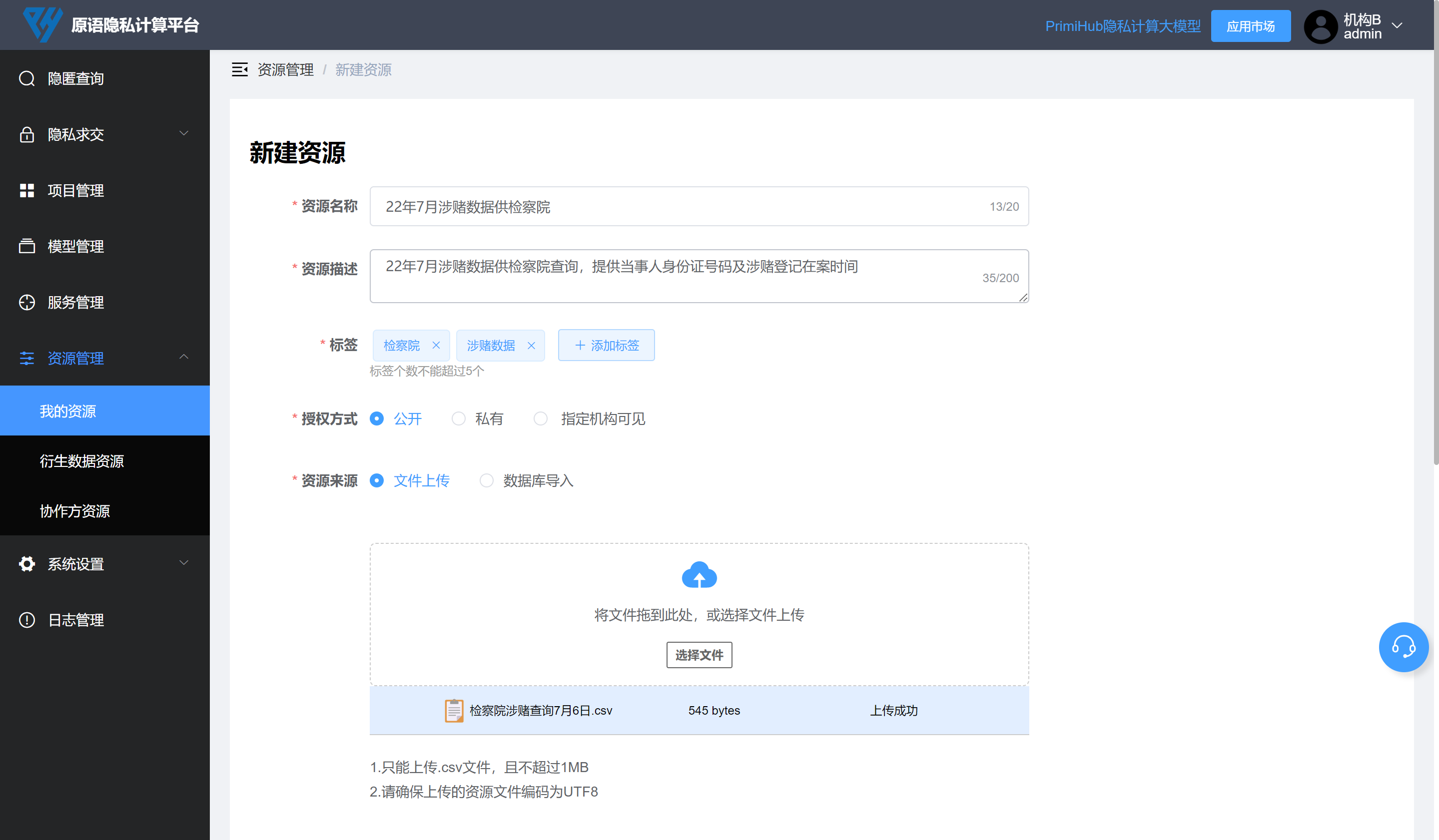
打开「节点 1」网页(检查院)在「隐匿查询」发起一次查询任务,在「选择查询资源」处选择上一步模拟公安机关上传的数据资源,最后点击「查询」按钮。

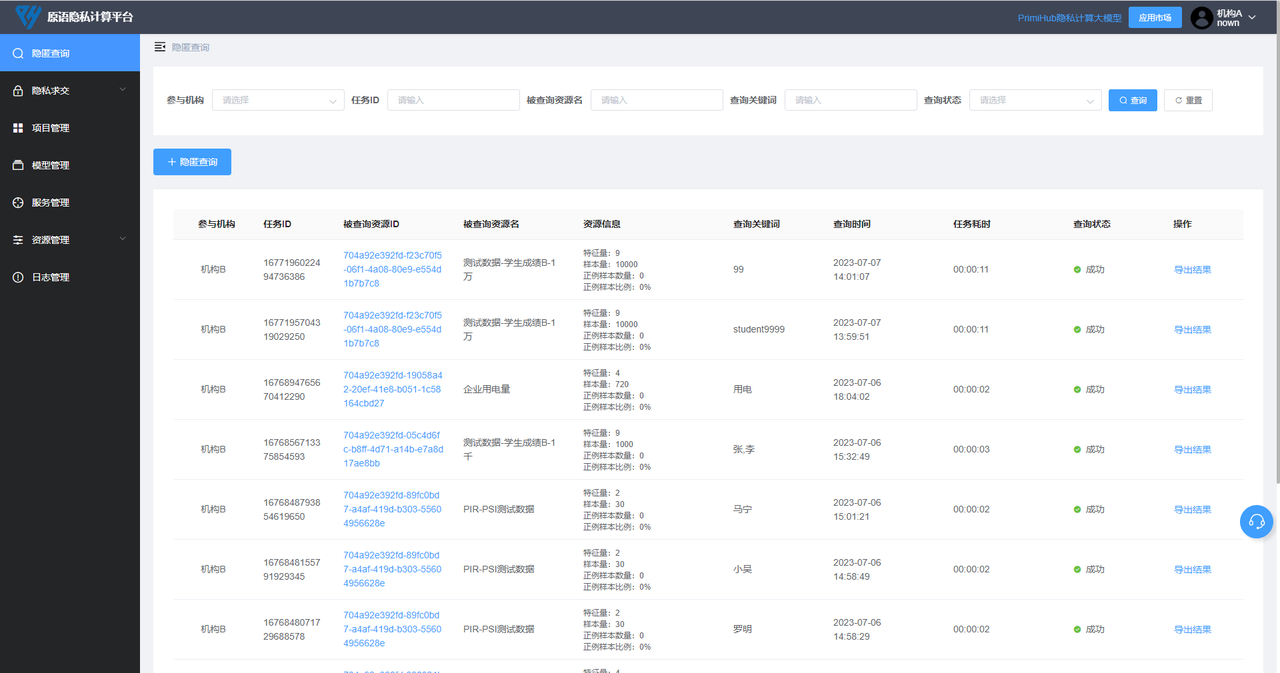
在「节点 1」网页(检查院)的「隐匿查询」下可以查看上一步创建的「匿踪查询」任务状态,任务运行结束后,点击「导出结果」即可下载结果文件,查看匿踪查询返回的记录。
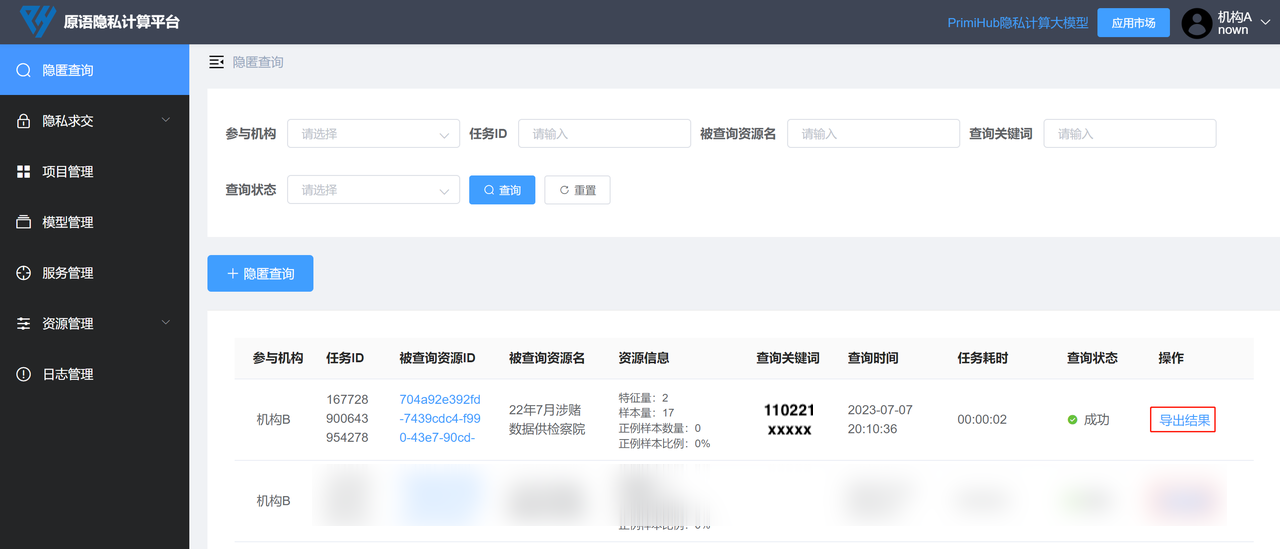
至此,我们就用 PrimiHub 管理平台完成了一次完整的「匿踪查询」任务。模拟了检察院在公安机关提供的涉赌记录数据中,查询目标对象(110221xxxxx)的涉赌信息。在查询过程中,检察院仅获得查询对象的信息,公安机关也看不到检察院的查询记录,保证了检察院的办案独立性。
PrimiHub 是由原语科技开源的隐私计算平台,具有开箱即用、功能丰富、容易上手、灵活配置等特点。
隐私计算作为前沿技术,其开发难度可想而知,开源不易如果体验后觉得 PrimiHub 还不错,就点一个 Star✨ 吧!
GitHub 地址:https://github.com/primihub/primihub
在国内外科技巨头纷纷布局隐私计算产业的当下,花些时间学习一下「隐私计算」属实是波只赚不亏的技术投资。虽然目前隐私计算受限于性能等因素还远没到普及的程度,但从各国对于隐私保护的重视程度,隐私数据安全合规的使用和流动注定是未来的趋势。相信待时机成熟之时,隐私计算会和现在的大模型一样,迎来属于自己的时代。
在大数据和 AI 的时代背景下,数据已经成为了重要财富,大到政务数据、企业核心数据,小到个人信息、银行卡余额,这些数据无一例外都是“隐私数据”,如果在使用和流转时发生泄漏都会造成巨大的损失。