转载请注明出处:
大:一个表可以有上亿行,上百万列。
面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
数据类型单一:HBase中的数据都是字符串,没有类型。
HBase也可以作为一个数据库使用,但是为了应对海量数据,他存储数据的方式 与我们理解的传统关系型数据库有很大的区别。虽然他也有表、列这样的逻辑结 构,但是整体上,他是以一种k-v键值对的方式来存储数据的:
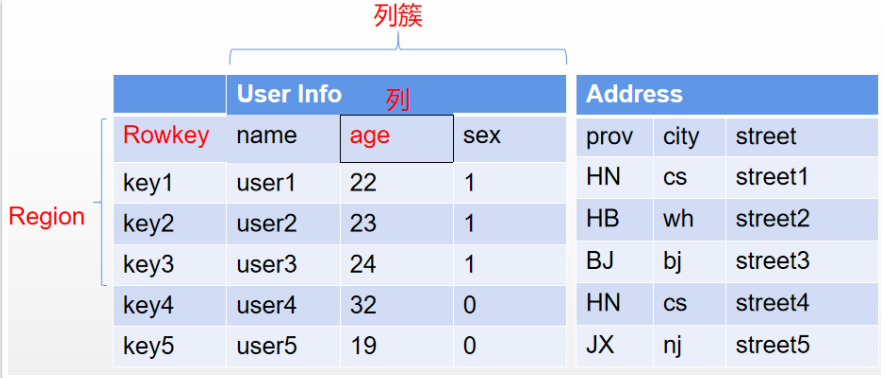
纵向来看,HBase中的每张表由Rowkey和若干个列族或者称为列簇组成。其中 Rowkey是每一行数据的唯一标识,在对数据进行管理时,必须自行保证Rowkey的 唯一性。接下来HBase依然会以不同的列来管理数据,但是这些列分别归属于不同 的列簇。在HBase中,同一张表的数据,只需要保证列簇是相同的,而列簇下的 列,可以是不相同的。所以由此可以扩展出非常多的列。在HBase中,对于同一张 表,不建议定义过多的列簇,通常不要超过三个。而更多的数据,可以以列的方式 来扩展。
从横向来看,HBase中的记录,会划分为一个一个的Region,存储在不同的 RegionServer上。并且会在不同的RegionServer之前形成备份,以Region为单位 提供了故障后自动恢复的机制。
最后,从整体来看,HBase虽然还是以HDFS作为文件存储,但是他存储的数据不 再是简单的文本文件,而是经过HBase优化压缩过的二进制文件,所以他的存储文 件通常是不能够直接查看的。
与 NoSQL 数据库一样,Row Key 是用来检索记录的主键。访问 HBase table 中的行,只有三种方式:
通过单个 Row Key 访问。
通过 Row Key 的 range 全表扫描。
Row Key 可以使任意字符串(最大长度是64KB,实际应用中长度一般为 10 ~ 100bytes),在HBase 内部,Row Key 保存为字节数组。
在存储时,数据按照 Row Key 的字典序(byte order)排序存储。设计 Key 时,要充分排序存储这个特性,将经常一起读取的行存储到一起(位置相关性)。
注意 字典序对 int 排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,20,21,…, 9,91,92,93,94,95,96,97,98,99。要保存整形的自然序,Row Key 必须用 0 进行左填充。
行的一次读写是原子操作(不论一次读写多少列)。这个设计决策能够使用户很容易理解程序在对同一个行进行并发更新操作时的行为。
RowKey的作用可以归纳如下两点:
Hbase在读写数据时需要通过RowKey找到对应的Region;MemStore和HFile中的数据都是按照 RowKey 的字典序排序。在HBase中,一个Region就相当于一个数据分片,每个Region都有StartRowKey和StopRowKey(用来表示 Region存储的RowKey的范围),HBase表里面的数据是按照RowKey来分散存储到不同的Region里面的。
而将数据记录均衡的分散到不同的Region中**避免热点现象**就是RowKey最主要的作用。
HBase 表中的每个列都归属于某个列族。列族是表的 Schema 的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀,例如 courses:history、courses:math 都属于 courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。在实际应用中,列族上的控制权限能帮助我们管理不同类型的应用, 例如,允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、 一些应用则只允许浏览数据(甚至可能因为隐私的原因不能浏览所有数据)。
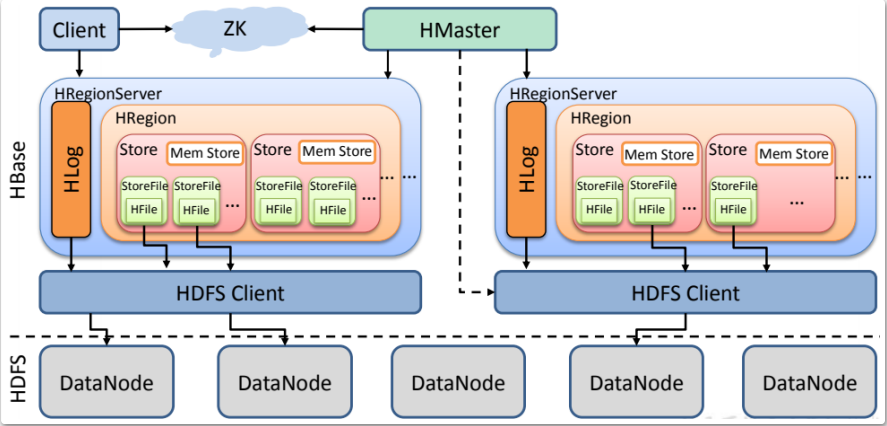
从HBase的架构图上可以看出,HBase中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等;
其中,
HBase中的每张表都通过行键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
Table 在行的方向上分割为多个HRegion,每个HRegion分散在不同的RegionServer中。每个HRegion由多个Store构成,每个Store由一个memStore和0或多个StoreFile组成,每个Store保存一个Columns Family。
HBase是一款开源高可靠性、扩展性、高性能和灵活性的分布式非关系型数据库,本文围绕数据库选型以及使用HBase的痛点展开,从四个方面对HBase的使用进行优化,取得了一些不错效果。
本文对 HBase Compaction 的原理、流程以及限流的策略进行了详细的介绍,列举了几个线上进行调优的案例,最后对 Compaction 的相关参数进行了总结。