转载请注明出处:
hbase shell # 或 bin/hbase shell复制
help复制
list复制
create 'user','basicinfo'复制

desc 'user'复制

3.1.插入数据
# 语法为: put 表名,rowkey,列簇:列,值 #插入一条数据 put 'user','1001','basicinfo:name','roy' put 'user','1001','basicinfo:age',18 put 'user','1001','basicinfo:salary',10000 #插入第二条数据 put 'user','1002','basicinfo:name','sophia' put 'user','1002','basicinfo:sex','female' put 'user','1002','basicinfo:job','manager' #插入第三条数据 put 'user','1003','basicinfo:name','yula' put 'user','1003','basicinfo:school','phz school'复制
hbase 中访问数据有两种基本的方式:
scan`可以设置 begin 和 end 参数来访问一个范围内所有的数据。get 本质上就是 begin 和 end 相等的一种特殊的 scan。
对于表名和列名必须使用单引号
1、HBase查询数据只能依据Rowkey来进行查询,而Rowkey是由客户 端直接指定的,所以在使用HBase时, Rowkey如何设计非常重要,要 带上重要的业务信息。
2、scan指令后面的查询条件,STARTROW和STOPROW是必须大写 的。查询的结果是左开右闭的。
#可以查看所有列 get 'user','1001'复制

4.2.查找某一列的值
#查看指定列 get 'user','1001','basicinfo:name'复制

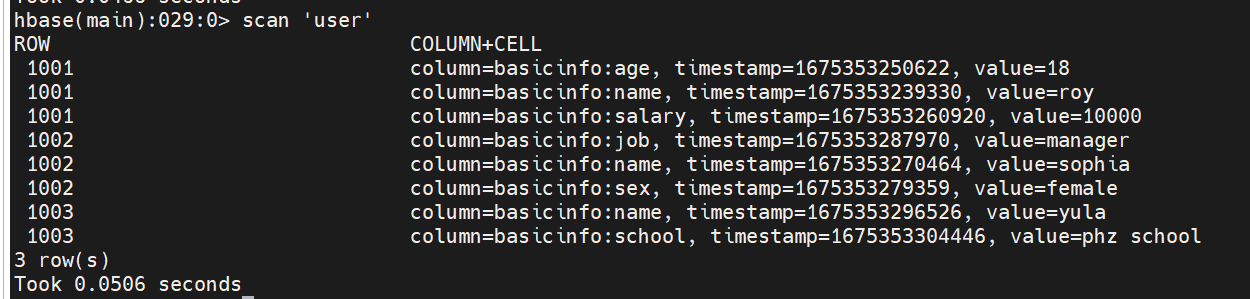
#查询整表数据 scan 'user'复制
scan 'user',{COLUMN=>'basicinfo'}复制
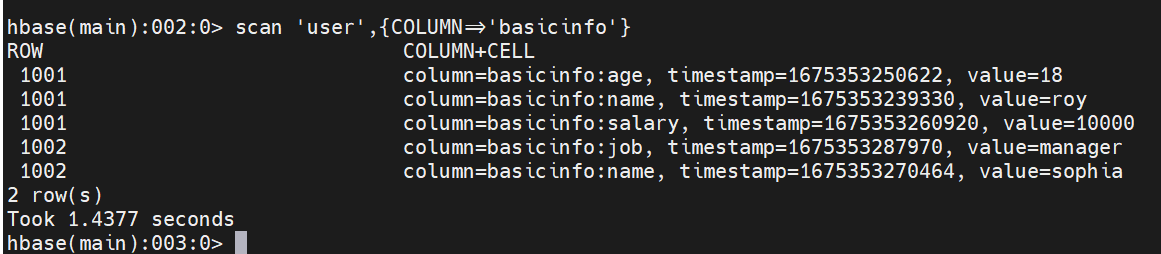
需要注意:COLUMN必須大写
scan 'user',{COLUMN=>'basicinfo:age'}复制

scan 'user',{STARTROW => '1001',STOPROW => '1002'}复制
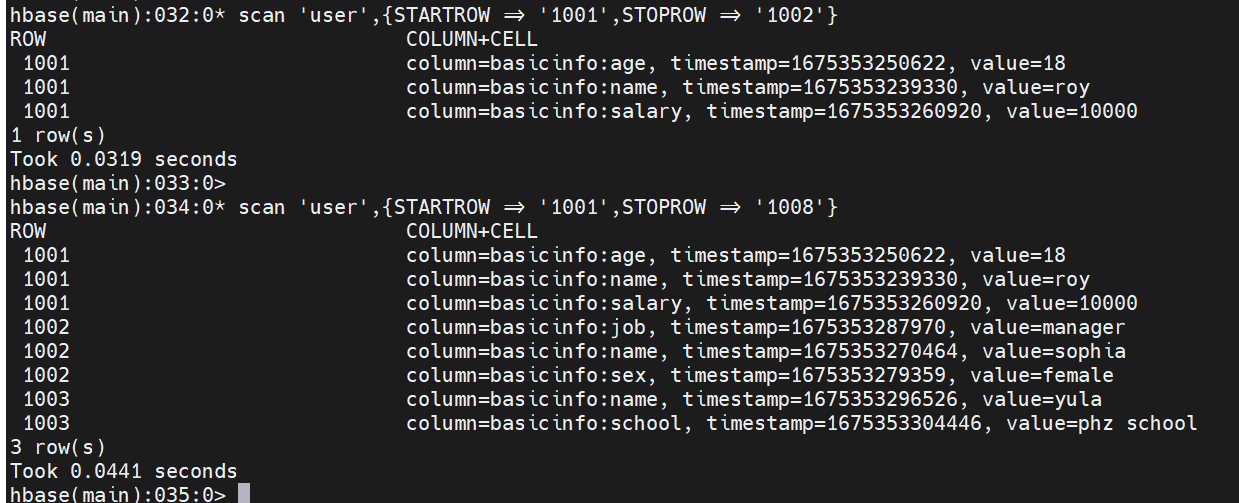
scan 'user',{STARTROW => '1001',STOPROW => '1002',LIMIT=>1}复制

scan 'user',FILTER=>"ValueFilter(=,'binary:18')" scan 'user', FILTER=>"ValueFilter(=,'substring:roy')" scan 'user', FILTER=>"ColumnPrefixFilter('age')"复制



count 'user'复制

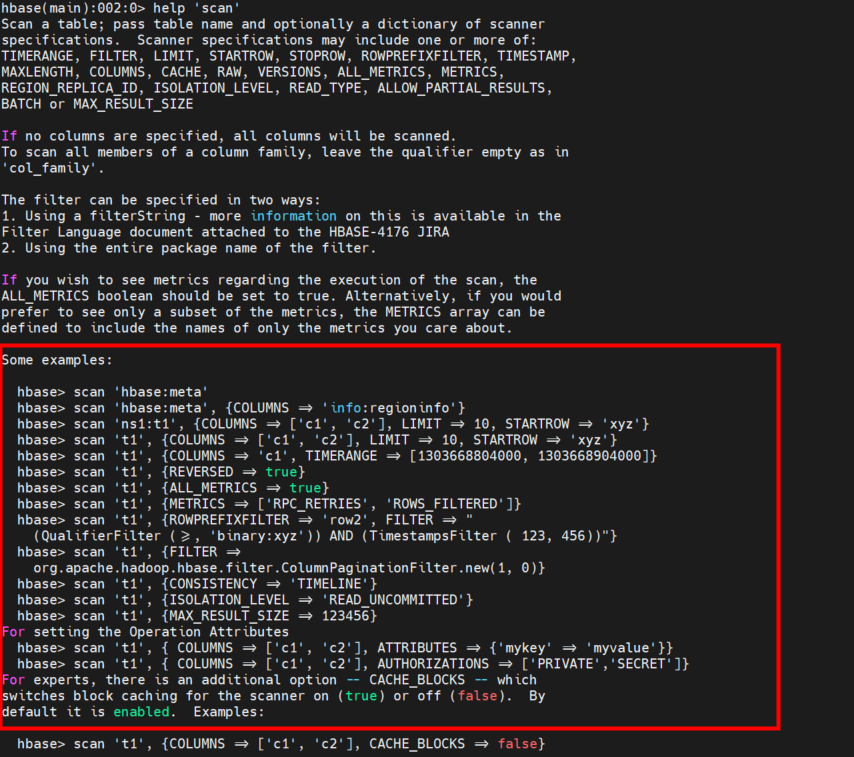
help 'get' help 'scan'复制

delete 'user','1002','basicinfo:sex'复制
deleteall 'user','1003'复制
truncate 'user'复制
disable 'user' drop 'user'复制
enable 'user'复制
exists 'user'复制
HBase是一款开源高可靠性、扩展性、高性能和灵活性的分布式非关系型数据库,本文围绕数据库选型以及使用HBase的痛点展开,从四个方面对HBase的使用进行优化,取得了一些不错效果。
本文对 HBase Compaction 的原理、流程以及限流的策略进行了详细的介绍,列举了几个线上进行调优的案例,最后对 Compaction 的相关参数进行了总结。