转载请注明出处:
InfluxDB有以下几个常用的端点,它们的作用和传参方式如下:
端点:
作用:用于检查InfluxDB实例的状态,返回InfluxDB的构建类型和版本信息。
传参:无需传参,仅发送GET请求即可。
调用示例:
curl http://localhost:8086/ping复制
端点:
作用:用于将数据写入InfluxDB。
传参:
请求方式:发送POST请求。
请求头:
Content-Type:设置为application/x-www-form-urlencoded或text/plain,表示请求体中的数据格式为InfluxDB的行协议(Line Protocol)。
请求体:需要将要写入的数据按照InfluxDB的行协议格式进行编码,并作为请求体发送。
当有标签(tag)和字段(field)如下所示时,可以通过在数据点中使用逗号分隔并以键值对的形式传递参数:
curl -XPOST 'http://localhost:8086/write?db=my_database' \ --data-binary ' measurement_name,host=example_host,ip=192.168.1.100 name="John Doe",num=42 1627842300000000000 '复制
也可以添加更多的数据点,每个数据点之间使用换行符进行分隔,以传递多个标签和字段的参数。
端点:
作用:用于执行查询操作,从InfluxDB中检索数据。
传参:
请求方式:发送POST请求。
请求头:
Content-Type:设置为application/x-www-form-urlencoded或application/json,表示请求体中的数据格式为InfluxDB查询语句的格式(InfluxQL或Flux)。
请求体:将查询语句编写为InfluxQL或Flux格式,并作为请求体发送。
curl -XPOST 'http://localhost:8086/query' \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'q=SELECT * FROM measurement_name WHERE time > now() - 1h'复制
端点(批量查询):
作用:用于在单个请求中执行多个查询操作。
传参:
请求方式:发送POST请求。
请求头:
Content-Type:设置为application/x-www-form-urlencoded或application/json,表示请求体中的数据格式为InfluxDB查询语句的格式(InfluxQL或Flux)。
请求体:将多个查询语句按照InfluxQL或Flux格式编写,并使用分号(;)作为分隔符,将它们放在请求体中一起发送。
curl -XPOST 'http://localhost:8086/query?db=my_database' \ --data-raw ' [ { "measurement": "measurement_name1", "tags": { "tag_key": "tag_value" }, "fields": [ "field_key1", "field_key2" ], "time": "2022-01-01T00:00:00Z", "query": "SELECT field_key1, field_key2 FROM measurement_name1 WHERE tag_key = 'tag_value'" }, { "measurement": "measurement_name2", "tags": { "tag_key": "tag_value" }, "fields": [ "field_key1", "field_key2" ], "time": "2022-01-01T00:00:00Z", "query": "SELECT field_key1, field_key2 FROM measurement_name2 WHERE tag_key = 'tag_value'" } ] '复制
对每个部分的详细说明:
-XPOST:指定 HTTP 请求方法为 POST。
http://localhost:8086/query?db=my_database:设置目标 URL,其中 http://localhost:8086 是 InfluxDB 服务地址,query 是端点路径,db=my_database 是查询参数,指定要查询的数据库名称为 my_database。
--data-raw:用于发送原始数据的 curl 选项。在这里,我们使用它来传递批量查询的 JSON 数据。
这是实际的批量查询 JSON 数据示例。其中包含两个查询对象,每个对象都有以下属性:
measurement:测量名称;
tags:标签键值对;
fields:字段列表;
time:时间戳(可选);
query:实际的 InfluxDB 查询语句。
请根据实际需求替换示例中的参数,并确保提供正确的查询语句和数据库名称。
响应将返回多个查询结果,每个查询结果都以 JSON 格式表示。你可以通过解析响应来获取每个查询的结果。
5.1 unable to parse authentication credentials
报错 "unable to parse authentication credentials" 表明在发送 InfluxDB 查询请求时,认证凭据解析错误。这是由于未正确配置或提供身份验证信息导致的。需要在发送 curl 请求时,提供了正确的用户名和密码来进行身份验证。可以使用 -u 参数来指定用户名和密码。以下是一个示例:
curl -XPOST 'http://localhost:8086/query' \ -H 'Content-Type: application/x-www-form-urlencoded' \ -u username:password \ --data-urlencode 'q=SELECT * FROM measurement_name WHERE time > now() - 1h'复制
请确保在 InfluxDB 的配置文件中启用了身份验证,并且提供了正确的用户名和密码。默认情况下,InfluxDB 的身份验证是禁用的,因此需要手动启用并配置用户凭据。
如果问题仍然存在,请检查用户名和密码是否正确,以及 InfluxDB 配置文件中是否正确配置了身份验证。
5.2 database name required
报错 "database name required" 表明在发送 InfluxDB 查询请求时,未提供数据库名称。查询语句需要指定要使用的数据库。
curl -XPOST 'http://localhost:8086/query' \ -H 'Content-Type: application/x-www-form-urlencoded' \ -u username:password \ --data-urlencode 'q=SELECT * FROM measurement_name WHERE time > now() - 1h' \ --data-urlencode 'db=your_database_name'复制
在上述示例中,将 your_database_name 替换为实际的数据库名称,并确保提供了正确的数据库名称。
-u 需要转换为 Authorization 的请求头,使用python的base64计算的具体方法为:
import base64 username = 'admin' password = 'password' credentials = username + ':' + password base64_credentials = base64.b64encode(credentials.encode()).decode() authorization = 'Basic ' + base64_credentials print(authorization)复制
根据 生成的 Authorization 配置到 postman 中。
将 查询 的sql,db配置到查询的body
header部分:
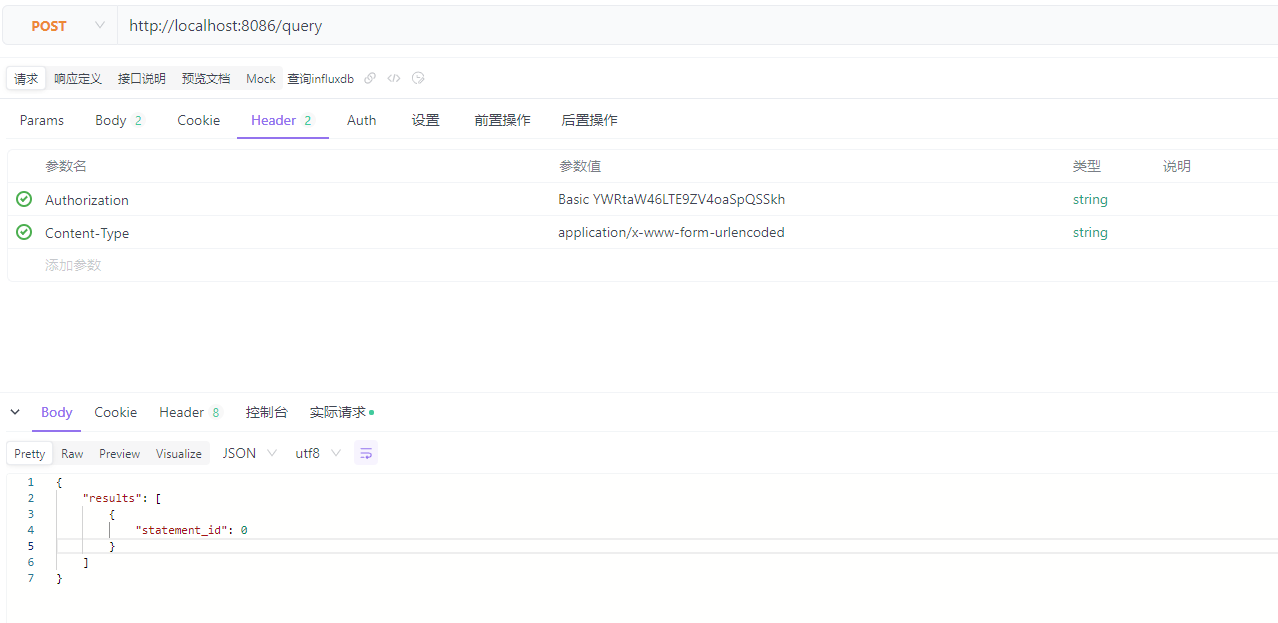
body部分
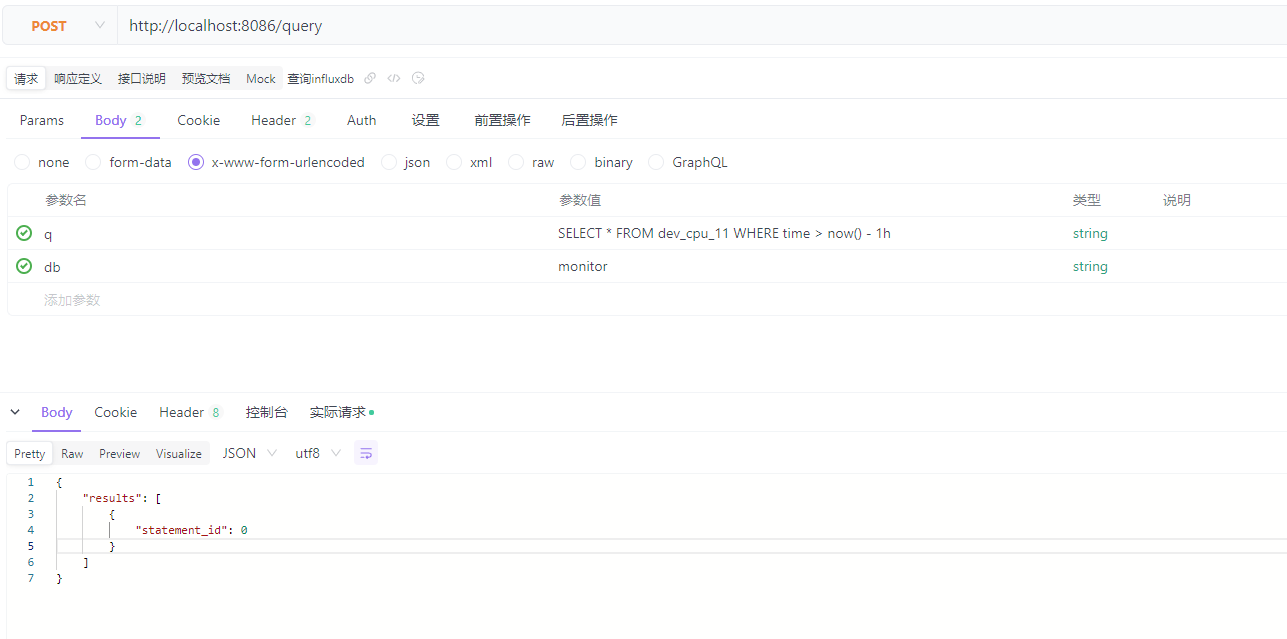
参考:
https://docs.influxdata.com/influxdb/v1.7/tools/api/