2014年,Ross Girshick提出RCNN,成为目标检测领域的开山之作。一年后,借鉴空间金字塔池化思想,Ross Girshick推出设计更为巧妙的Fast RCNN(https://github.com/rbgirshick/fast-rcnn),极大地提高了检测速度。Fast RCNN的提出解决了RCNN结构固有的三个弊端:
同前面RCNN实现一样(见 https://www.cnblogs.com/Haitangr/p/17690028.html),本文将基于Pytorch框架,实现Fast RCNN算法,完成对17flowes数据集的花朵目标检测任务。
如下为RCNN算法和Fast RCNN算法流程对比图:
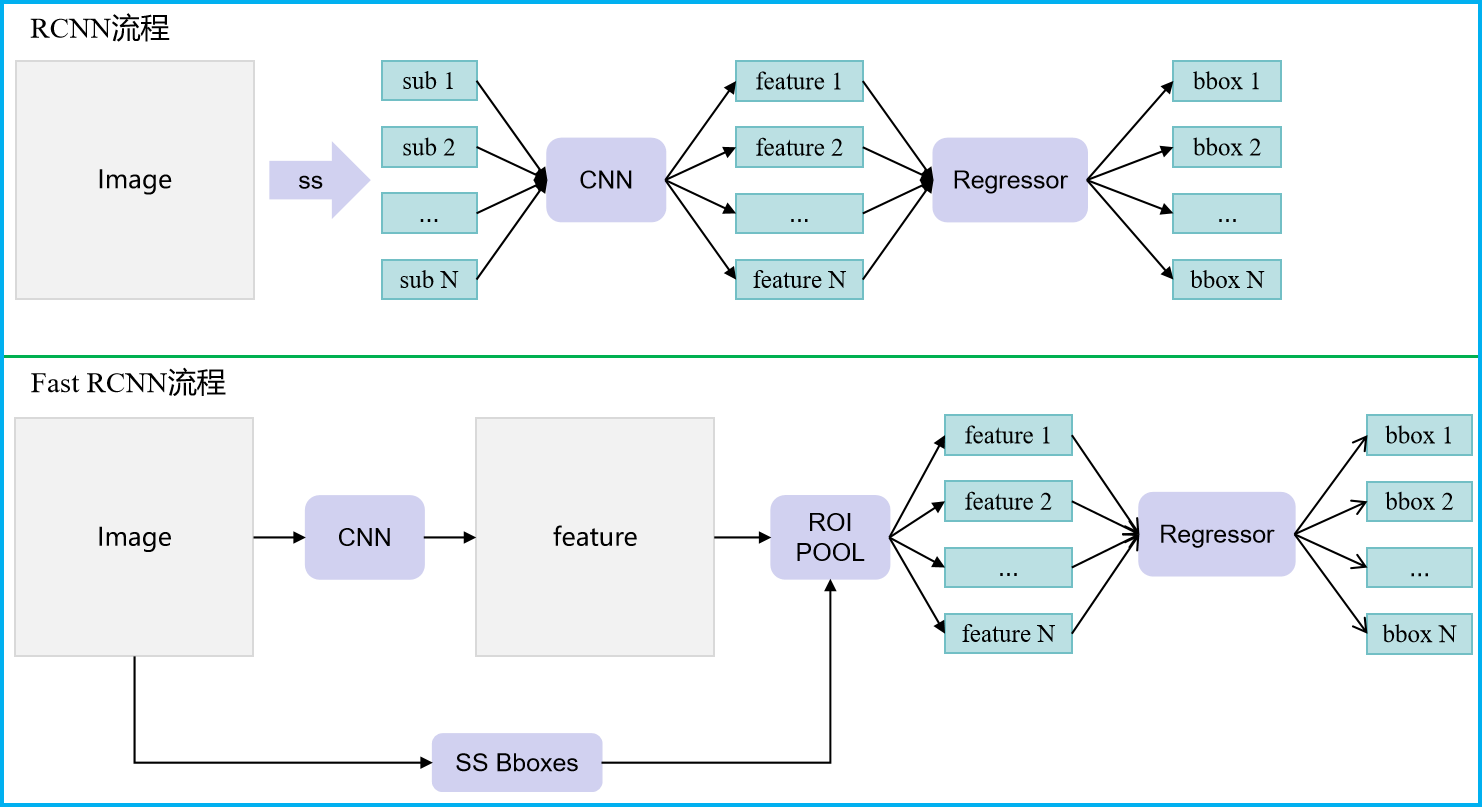
RCNN算法实现过程中,需要将生成的所有推荐区域(~2k)缩放到同一大小后,全部走一遍卷积网络CNN,以提取相应特征进行边界框预测,这个过程极为耗时。同时,由于这2k张图片均来源于同一张输入,卷积网络会进行大量重复性计算。Fast RCNN则完全不同,其输入图片只进行一次CNN计算,以获得整幅图像的特征。而推荐区域的特征则直接利用区域池化技术,根据相应的边界框在全图特征上进行提取,大大降低了计算成本。此外,Fast RCNN采用多任务损失对分类模型和回归模型同时进行优化,避免了繁琐的多阶段训练过程。
下面是本文中Fast RCNN的实现流程:
Fast RCNNt同RCNN一样采用选择性搜索(selective search,后面简称为ss)的办法产生候选区域,ss方法的详细思路同样请参考 https://www.cnblogs.com/Haitangr/p/17690028.html 。不同的是,Fast RCNN只需要记录候选区域的标签(物体/背景)、候选区域的边界框位置和对应的真实边界框位置,而不需要保存推荐区域图像。具体代码实现如下:


# SelectiveSearch.py import os import numpy as np import pandas as pd import cv2 as cv import shutil from Utils import cal_IoU from skimage import io from multiprocessing import Process import threading import matplotlib.pyplot as plt import matplotlib.patches as patches from Config import * class SelectiveSearch: def __init__(self, root, max_pos_regions: int = None, max_neg_regions: int = None, threshold=0.5): """ 采用ss方法生成候选区域文件 :param root: 训练/验证数据集所在路径 :param max_pos_regions: 每张图片最多产生的正样本候选区域个数, None表示不进行限制 :param max_neg_regions: 每张图片最多产生的负样本候选区域个数, None表示不进行限制 :param threshold: IoU进行正负样本区分时的阈值 """ self.source_root = os.path.join(root, 'source') self.ss_root = os.path.join(root, 'ss') self.csv_path = os.path.join(self.source_root, "gt_loc.csv") self.max_pos_regions = max_pos_regions self.max_neg_regions = max_neg_regions self.threshold = threshold self.info = None @staticmethod def cal_proposals(img) -> np.ndarray: """ 计算后续区域坐标 :param img: 原始输入图像 :return: candidates, 候选区域坐标矩阵n*4维, 每列分别对应[x, y, w, h] """ # 生成候选区域 ss = cv.ximgproc.segmentation.createSelectiveSearchSegmentation() ss.setBaseImage(img) ss.switchToSelectiveSearchFast() proposals = ss.process() candidates = set() # 对区域进行限制 for region in proposals: rect = tuple(region) if rect in candidates: continue candidates.add(rect) candidates = np.array(list(candidates)) return candidates def save(self, num_workers=1, method="thread"): """ 生成目标区域并保存 :param num_workers: 进程或线程数 :param method: 多进程-process或者多线程-thread :return: None """ self.info = pd.read_csv(self.csv_path, header=0, index_col=None) index = self.info.index.to_list() span = len(index) // num_workers # 多进程生成图像 if "process" in method.lower(): print("=" * 8 + "开始多进程生成候选区域图像" + "=" * 8) processes = [] for i in range(num_workers): if i != num_workers - 1: p = Process(target=self.save_proposals, kwargs={'index': index[i * span: (i + 1) * span]}) else: p = Process(target=self.save_proposals, kwargs={'index': index[i * span:]}) p.start() processes.append(p) for p in processes: p.join() # 多线程生成图像 elif "thread" in method.lower(): print("=" * 8 + "开始多线程生成候选区域图像" + "=" * 8) threads = [] for i in range(num_workers): if i != num_workers - 1: thread = threading.Thread(target=self.save_proposals, kwargs={'index': index[i * span: (i + 1) * span]}) else: thread = threading.Thread(target=self.save_proposals, kwargs={'index': index[i * span: (i + 1) * span]}) thread.start() threads.append(thread) for thread in threads: thread.join() else: print("=" * 8 + "开始生成候选区域图像" + "=" * 8) self.save_proposals(index=index) return None def save_proposals(self, index, show_fig=False): """ 生成候选区域图片并保存相关信息 :param index: 文件index :param show_fig: 是否展示后续区域划分结果 :return: None """ for row in index: name = self.info.iloc[row, 0] label = self.info.iloc[row, 1] # gt值为[x, y, w, h] gt_box = self.info.iloc[row, 2:].values im_path = os.path.join(self.source_root, name) img = io.imread(im_path) # 计算推荐区域坐标矩阵[x, y, w, h] proposals = self.cal_proposals(img=img) # 计算proposals与gt的IoU结果 IoU = cal_IoU(proposals, gt_box) # 根据IoU阈值将proposals图像划分到正负样本集 p_boxes = proposals[np.where(IoU >= self.threshold)] n_boxes = proposals[np.where(IoU < self.threshold)] # 展示proposals结果 if show_fig: fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6)) ax.imshow(img) for (x, y, w, h) in p_boxes: rect = patches.Rectangle((x, y), w, h, fill=False, edgecolor='red', linewidth=1) ax.add_patch(rect) for (x, y, w, h) in n_boxes: rect = patches.Rectangle((x, y), w, h, fill=False, edgecolor='green', linewidth=1) ax.add_patch(rect) plt.show() # 根据图像名称创建文件夹, 保存原始图片/真实边界框/推荐区域边界框/推荐区域标签信息 folder = name.split("/")[-1].split(".")[0] save_root = os.path.join(self.ss_root, folder) os.makedirs(save_root, exist_ok=True) # 保存原始图像 im_save_path = os.path.join(save_root, folder + ".jpg") io.imsave(fname=im_save_path, arr=img, check_contrast=False) # loc.csv用于存储边界框信息 loc_path = os.path.join(save_root, "ss_loc.csv") # 记录正负样本信息 locations = [] header = ["label", "px", "py", "pw", "ph", "gx", "gy", "gw", "gh"] num_p = num_n = 0 for p_box in p_boxes: num_p += 1 locations.append([label, *p_box, *gt_box]) if self.max_pos_regions is None: continue if num_p >= self.max_pos_regions: break # 记录负样本信息, 负样本为背景, label置为0 for n_box in n_boxes: num_n += 1 locations.append([0, *n_box, *gt_box]) if self.max_neg_regions is None: continue if num_n >= self.max_neg_regions: break print("{name}: {num_p}个正样本, {num_n}个负样本".format(name=name, num_p=num_p, num_n=num_n)) pf = pd.DataFrame(locations) pf.to_csv(loc_path, header=header, index=False) if __name__ == '__main__': data_root = "./data" ss_root = os.path.join(data_root, "ss") if os.path.exists(ss_root): print("正在删除{}目录下原有数据".format(ss_root)) shutil.rmtree(ss_root) print("正在利用选择性搜索方法创建数据集: {}".format(ss_root)) select = SelectiveSearch(root=data_root, max_pos_regions=MAX_POSITIVE, max_neg_regions=MAX_NEGATIVE, threshold=IOU_THRESH) select.save(num_workers=os.cpu_count(), method="thread")复制
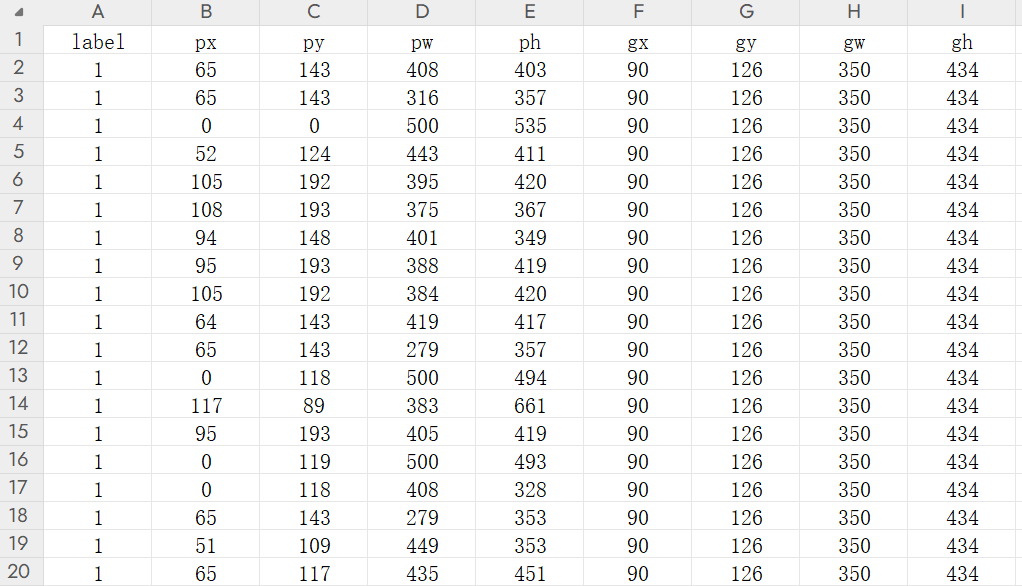
通过以上方法,会在./data/ss目录下为每一张图片生成一个文件夹,文件夹内存放原始图像(.jpg文件)和边界框信息(ss_loc.csv文件)。其中边界框信息文件结构如图,依次存放标签(label)、推荐区域边界框(gx, gy, gw, gh)和真实边界框(gx, gy, gw, gh),这些数据将用于后续模型分类和回归。
从前面的流程图可以看出,Fast RCNN输入有两个,分别是图像和推荐区域边界框,前者用于计算特征图,后者用于在特征图上进行目标区域特征提取。此外,在多任务损失中,还需要区域标签进行分类损失计算,需要区域边界框偏移值进行回归损失计算。因此,每一帧训练图像需要包含:原始图像、标签、推荐区域边界框和边界框偏移值。本文对图像进行了随机翻转和固定尺寸缩放,以达到数据增强的目的,相应的边界框等信息也需要在数据增强过程中重新计算。下面通过代码介绍数据准备过程中的一些细节处理。
假设输入图片尺寸为(rows, cols, 3),边界框为(x, y, w, h),在进行水平翻转时,原边界框左上角坐标点(x, y)会被翻转到右上角(rows, cols - 1 - x),翻转后左上角坐标应为(rows, cols - 1 - x - w),而w和h不改变。
随机水平翻转代码如下:
def random_horizontal_flip(self, im: np.ndarray, ss_boxes: np.ndarray, gt_boxes: np.ndarray): """ 随机水平翻转图像 :param im: 输入图像 :param ss_boxes: 推荐区域边界框 :param gt_boxes: 边界框真值 :return: 翻转后图像和边界框结果 """ if random.uniform(0, 1) < self.prob_horizontal_flip: rows, cols = im.shape[:2] # 左右翻转图像 im = np.fliplr(im) # 边界框位置重新计算 ss_boxes[:, 0] = cols - 1 - ss_boxes[:, 0] - ss_boxes[:, 2] gt_boxes[:, 0] = cols - 1 - gt_boxes[:, 0] - gt_boxes[:, 2] else: pass return im, ss_boxes, gt_boxes复制
假设输入图片尺寸为(rows, cols, 3),边界框为(x, y, w, h),在进行垂直翻转时,原边界框左上角坐标点(x, y)会被翻转到左下角(rows - 1 - y, cols),翻转后左上角坐标应为(rows - 1 - y - h, cols),而w和h不改变。
随机垂直翻转代码如下:
def random_vertical_flip(self, im: np.ndarray, ss_boxes: np.ndarray, gt_boxes: np.ndarray): """ 随机垂直翻转图像 :param im: 输入图像 :param ss_boxes: 推荐区域边界框 :param gt_boxes: 边界框真值 :return: 翻转后图像和边界框结果 """ if random.uniform(0, 1) < self.prob_vertical_flip: rows, cols = im.shape[:2] # 上下翻转图像 im = np.flipud(im) # 重新计算边界框位置 ss_boxes[:, 1] = rows - 1 - ss_boxes[:, 1] - ss_boxes[:, 3] gt_boxes[:, 1] = rows - 1 - gt_boxes[:, 1] - gt_boxes[:, 3] else: pass return im, ss_boxes, gt_boxes复制
本文中采用vgg16提取图像特征,在图像输入vgg16模型前,需要缩放到固定大小(文中采用 512 * 512)。假设输入图片尺寸为(rows, cols, 3),边界框为(x, y, w, h),缩放后尺寸为(im_width, im_height, 3),由于缩放过程中x和w是等比例缩放,y和h也是等比例缩放,则缩放后边界框为(x * im_width / cols, y * im_height / rows, w * im_width / cols, h * im_height / rows)。
图像缩放代码如下:
def resize(im: np.ndarray, im_width: int, im_height: int, ss_boxes: np.ndarray, gt_boxes: Union[np.ndarray, None]): """ 对图像进行缩放 :param im: 输入图像 :param im_width: 目标图像宽度 :param im_height: 目标图像高度 :param ss_boxes: 推荐区域边界框->[n, 4] :param gt_boxes: 真实边界框->[n, 4] :return: 图像和两种边界框经过缩放后的结果 """ rows, cols = im.shape[:2] # 图像缩放 im = cv.resize(src=im, dsize=(im_width, im_height), interpolation=cv.INTER_CUBIC) # 计算缩放过程中(x, y, w, h)尺度缩放比例 scale_ratio = np.array([im_width / cols, im_height / rows, im_width / cols, im_height / rows]) # 边界框也等比例缩放 ss_boxes = (ss_boxes * scale_ratio).astype("int") if gt_boxes is None: return im, ss_boxes gt_boxes = (gt_boxes * scale_ratio).astype("int") return im, ss_boxes, gt_boxes复制
Fast RCNN中边界框偏移值采用比例和对数方式计算,避免了边界框数值大小对训练的影响。
边界框偏移值代码如下:
def calc_offsets(ss_boxes: np.ndarray, gt_boxes: np.ndarray) -> np.ndarray: """ 计算候选区域与真值间的位置偏移 :param ss_boxes: 候选边界框 :param gt_boxes: 真值 :return: 边界框偏移值 """ offsets = np.zeros_like(ss_boxes, dtype="float32") # 基于比例计算偏移值可以不受位置大小的影响 offsets[:, 0] = (gt_boxes[:, 0] - ss_boxes[:, 0]) / ss_boxes[:, 2] offsets[:, 1] = (gt_boxes[:, 1] - ss_boxes[:, 1]) / ss_boxes[:, 3] # 使用log计算w/h的偏移值, 避免值过大 offsets[:, 2] = np.log(gt_boxes[:, 2] / ss_boxes[:, 2]) offsets[:, 3] = np.log(gt_boxes[:, 3] / ss_boxes[:, 3]) return offsets复制
我们需要构建包含原始图像(images)、标签(labels)、推荐区域边界框(ss_boxes)和边界框偏移值(offsets)的数据集,假设每个batch有N个原始输入图像,其中第 i 个图像产生Mi(i=1, 2, ..., N)个推荐区域。由于每个图象生成的推荐区域数量不固定,那么相应的标签、边界框、偏移值维度也不统一,无法直接继承torchvision.transforms.Dataset从而构建数据集,因为Dataset要求数据具有相同类型和形状。因此本文通过batch_size大小来控制每个batch数据量,将同一batch数据存在一个列表中,后续再迭代提取。
数据获取代码如下:
def get_fdata(self): """ 数据集准备 :return: 数据列表 """ fdata = [] if self.shuffle: random.shuffle(self.flist) for num in range(self.num_batch): # 按照batch大小读取数据 cur_flist = self.flist[num * self.batch_size: (num + 1) * self.batch_size] # 记录当前batch的图像/推荐区域标签/边界框/位置偏移 cur_ims, cur_labels, cur_ss_boxes, cur_offsets = [], [], [], [] for img_path, doc_path in cur_flist: # 读取图像 img = io.imread(img_path) # 读取边界框并堆积打乱框顺序 ss_info = pd.read_csv(doc_path, header=0, index_col=None) ss_info = ss_info.sample(frac=1).reset_index(drop=True) labels = ss_info.label.to_list() ss_boxes = ss_info.iloc[:, 1: 5].values gt_boxes = ss_info.iloc[:, 5: 9].values # 数据归一化 img = self.normalize(im=img) # 随机翻转数据增强 img, ss_boxes, gt_boxes = self.random_horizontal_flip(im=img, ss_boxes=ss_boxes, gt_boxes=gt_boxes) img, ss_boxes, gt_boxes = self.random_vertical_flip(im=img, ss_boxes=ss_boxes, gt_boxes=gt_boxes) # 将图像缩放到统一大小 img, ss_boxes, gt_boxes = self.resize(im=img, im_width=self.im_width, im_height=self.im_height, ss_boxes=ss_boxes, gt_boxes=gt_boxes) # 计算最终坐标偏移值 offsets = self.calc_offsets(ss_boxes=ss_boxes, gt_boxes=gt_boxes) # 转换为tensor im_tensor = torch.tensor(np.transpose(img, (2, 0, 1))) ss_boxes_tensor = torch.tensor(data=ss_boxes) cur_ims.append(im_tensor) cur_labels.extend(labels) cur_ss_boxes.append(ss_boxes_tensor) cur_offsets.extend(offsets) # 每个batch数据放一起方便后续训练调用 cur_ims = torch.stack(cur_ims) cur_labels = torch.tensor(cur_labels) cur_offsets = torch.tensor(np.array(cur_offsets)) fdata.append([cur_ims, cur_labels, cur_ss_boxes, cur_offsets]) return fdata复制
通过上述流程,本文实现实现了一个可迭代的数据集类,每次迭代返回一个batch的数据,用于模型训练使用,完整代码如下:
class GenDataSet: def __init__(self, root, im_width, im_height, batch_size, shuffle=False, prob_vertical_flip=0.5, prob_horizontal_flip=0.5): """ 初始化GenDataSet :param root: 数据路径 :param im_width: 目标图片宽度 :param im_height: 目标图片高度 :param batch_size: 批数据大小 :param shuffle: 是否随机打乱批数据 :param prob_vertical_flip: 随机垂直翻转概率 :param prob_horizontal_flip: 随机水平翻转概率 """ self.root = root self.im_width, self.im_height = (im_width, im_height) self.batch_size = batch_size self.shuffle = shuffle self.flist = self.get_flist() self.num_batch = self.calc_num_batch() self.prob_vertical_flip = prob_vertical_flip self.prob_horizontal_flip = prob_horizontal_flip def get_flist(self) -> list: """ 获取原始图像和推荐区域边界框 :return: [图像, 边界框]列表 """ flist = [] for roots, dirs, files in os.walk(self.root): for file in files: if not file.endswith(".jpg"): continue img_path = os.path.join(roots, file) doc_path = os.path.join(roots, "ss_loc.csv") if not os.path.exists(doc_path): continue flist.append((img_path, doc_path)) return flist def calc_num_batch(self) -> int: """ 计算batch数量 :return: 批数据数量 """ total = len(self.flist) if total % self.batch_size == 0: num_batch = total // self.batch_size else: num_batch = total // self.batch_size + 1 return num_batch @staticmethod def normalize(im: np.ndarray) -> np.ndarray: """ 将图像数据归一化 :param im: 输入图像->uint8 :return: 归一化图像->float32 """ if im.dtype != np.uint8: raise TypeError("uint8 img is required.") else: im = im / 255.0 im = im.astype("float32") return im @staticmethod def calc_offsets(ss_boxes: np.ndarray, gt_boxes: np.ndarray) -> np.ndarray: """ 计算候选区域与真值间的位置偏移 :param ss_boxes: 候选边界框 :param gt_boxes: 真值 :return: 边界框偏移值 """ offsets = np.zeros_like(ss_boxes, dtype="float32") # 基于比例计算偏移值可以不受位置大小的影响 offsets[:, 0] = (gt_boxes[:, 0] - ss_boxes[:, 0]) / ss_boxes[:, 2] offsets[:, 1] = (gt_boxes[:, 1] - ss_boxes[:, 1]) / ss_boxes[:, 3] # 使用log计算w/h的偏移值, 避免值过大 offsets[:, 2] = np.log(gt_boxes[:, 2] / ss_boxes[:, 2]) offsets[:, 3] = np.log(gt_boxes[:, 3] / ss_boxes[:, 3]) return offsets @staticmethod def resize(im: np.ndarray, im_width: int, im_height: int, ss_boxes: np.ndarray, gt_boxes: Union[np.ndarray, None]): """ 对图像进行缩放 :param im: 输入图像 :param im_width: 目标图像宽度 :param im_height: 目标图像高度 :param ss_boxes: 推荐区域边界框->[n, 4] :param gt_boxes: 真实边界框->[n, 4] :return: 图像和两种边界框经过缩放后的结果 """ rows, cols = im.shape[:2] # 图像缩放 im = cv.resize(src=im, dsize=(im_width, im_height), interpolation=cv.INTER_CUBIC) # 计算缩放过程中(x, y, w, h)尺度缩放比例 scale_ratio = np.array([im_width / cols, im_height / rows, im_width / cols, im_height / rows]) # 边界框也等比例缩放 ss_boxes = (ss_boxes * scale_ratio).astype("int") if gt_boxes is None: return im, ss_boxes gt_boxes = (gt_boxes * scale_ratio).astype("int") return im, ss_boxes, gt_boxes def random_horizontal_flip(self, im: np.ndarray, ss_boxes: np.ndarray, gt_boxes: np.ndarray): """ 随机水平翻转图像 :param im: 输入图像 :param ss_boxes: 推荐区域边界框 :param gt_boxes: 边界框真值 :return: 翻转后图像和边界框结果 """ if random.uniform(0, 1) < self.prob_horizontal_flip: rows, cols = im.shape[:2] # 左右翻转图像 im = np.fliplr(im) # 边界框位置重新计算 ss_boxes[:, 0] = cols - 1 - ss_boxes[:, 0] - ss_boxes[:, 2] gt_boxes[:, 0] = cols - 1 - gt_boxes[:, 0] - gt_boxes[:, 2] else: pass return im, ss_boxes, gt_boxes def random_vertical_flip(self, im: np.ndarray, ss_boxes: np.ndarray, gt_boxes: np.ndarray): """ 随机垂直翻转图像 :param im: 输入图像 :param ss_boxes: 推荐区域边界框 :param gt_boxes: 边界框真值 :return: 翻转后图像和边界框结果 """ if random.uniform(0, 1) < self.prob_vertical_flip: rows, cols = im.shape[:2] # 上下翻转图像 im = np.flipud(im) # 重新计算边界框位置 ss_boxes[:, 1] = rows - 1 - ss_boxes[:, 1] - ss_boxes[:, 3] gt_boxes[:, 1] = rows - 1 - gt_boxes[:, 1] - gt_boxes[:, 3] else: pass return im, ss_boxes, gt_boxes def get_fdata(self): """ 数据集准备 :return: 数据列表 """ fdata = [] if self.shuffle: random.shuffle(self.flist) for num in range(self.num_batch): # 按照batch大小读取数据 cur_flist = self.flist[num * self.batch_size: (num + 1) * self.batch_size] # 记录当前batch的图像/推荐区域标签/边界框/位置偏移 cur_ims, cur_labels, cur_ss_boxes, cur_offsets = [], [], [], [] for img_path, doc_path in cur_flist: # 读取图像 img = io.imread(img_path) # 读取边界框并堆积打乱框顺序 ss_info = pd.read_csv(doc_path, header=0, index_col=None) ss_info = ss_info.sample(frac=1).reset_index(drop=True) labels = ss_info.label.to_list() ss_boxes = ss_info.iloc[:, 1: 5].values gt_boxes = ss_info.iloc[:, 5: 9].values # 数据归一化 img = self.normalize(im=img) # 随机翻转数据增强 img, ss_boxes, gt_boxes = self.random_horizontal_flip(im=img, ss_boxes=ss_boxes, gt_boxes=gt_boxes) img, ss_boxes, gt_boxes = self.random_vertical_flip(im=img, ss_boxes=ss_boxes, gt_boxes=gt_boxes) # 将图像缩放到统一大小 img, ss_boxes, gt_boxes = self.resize(im=img, im_width=self.im_width, im_height=self.im_height, ss_boxes=ss_boxes, gt_boxes=gt_boxes) # 计算最终坐标偏移值 offsets = self.calc_offsets(ss_boxes=ss_boxes, gt_boxes=gt_boxes) # 转换为tensor im_tensor = torch.tensor(np.transpose(img, (2, 0, 1))) ss_boxes_tensor = torch.tensor(data=ss_boxes) cur_ims.append(im_tensor) cur_labels.extend(labels) cur_ss_boxes.append(ss_boxes_tensor) cur_offsets.extend(offsets) # 每个batch数据放一起方便后续训练调用 cur_ims = torch.stack(cur_ims) cur_labels = torch.tensor(cur_labels) cur_offsets = torch.tensor(np.array(cur_offsets)) fdata.append([cur_ims, cur_labels, cur_ss_boxes, cur_offsets]) return fdata def __len__(self): # 以batch数量定义数据集大小 return self.num_batch def __iter__(self): self.fdata = self.get_fdata() self.index = 0 return self def __next__(self): if self.index >= self.num_batch: raise StopIteration # 生成当前batch数据 value = self.fdata[self.index] self.index += 1 return value复制
Fast RCNN的训练流程是:CNN获取特征图 → ROI_POOL提取候选区域特征 → 获取分类器和回归器结果 → 多任务损失参数调优。可知,Fast RCNN模型结构中需要依次实现图像特征提取器features、ROI池化、分类器classifier和回归器regressor,训练过程中需要构建多任务损失函数。下文详细介绍相关结构和代码。
本文中采用vgg16_bn作为模型特征提取器,直接调用torchvison.models中预训练模型即可,代码如下:
# 采用vgg16_bn作为backbone self.features = models.vgg16_bn(pretrained=True).features复制
ROI池化的作用是在特征图上进行候选区域特征的抽取,同时将抽取的特征缩放到固定大小,方便全连接层类型的分类器和回归器使用。其具体实现过程如下:
以本文介绍的Fast RCNN模型为例,其输入图像张量大小为 [3, 512, 512],经过vgg16_bn特征提取得到输出feature维度为 [512, 16, 16]。过程中数据经过5次2*2的MaxPool,特征进行了32倍缩放,相应地原边界框位置和大小也会进行等比例缩放。
假设输入模型的某一边界框 ss_box = (50, 72, 260, 318),经过等比例缩放后对应到特征图上的候选边界框 ss_box' = (50/32, 72/32, 260/32, 318/32) = (1.56, 2.25, 8.13, 9.94)。ss_box'值存在小数,此时的处理方法是直接向下取整,得到ss_box' = (1, 2, 8, 9),也就是说特征图上对应的 roi_feature = features[:, 2: 2 + 9, 1: 1 + 8],对应维度为 [512, 9, 8]。该特征是需要输入分类器和回归器的,由于两者是全连接层结构,输入特征尺寸是固定的,因此需要使用一定方法将其缩放到对应尺寸。本文直接采用 torch.nn.AdaptiveMaxPool2d进行缩放,当然你也可以采取其他方式,比如插值方法。
ROI池化具体实现代码如下:
def roi_pool(self, im_features: Tensor, ss_boxes: list): """ 提取推荐区域特征图并缩放到固定大小 :param im_features: backbone输出的图像特征->[batch, channel, rows, cols] :param ss_boxes: 推荐区域边界框信息->[batch, num, 4] :return: 推荐区域特征 """ roi_features = [] for im_idx, im_feature in enumerate(im_features): im_boxes = ss_boxes[im_idx] for box in im_boxes: # 输入全图经过backbone后空间位置需进行缩放, 利用空间缩放比例将box位置对应到feature上 fx, fy, fw, fh = [int(p / self.spatial_scale) for p in box] # 缩放后维度不足1个pixel, 是由于int取整导致, 仍取1个pixel防止维度为0 if fw == 0: fw = 1 if fh == 0: fh = 1 # 在特征图上提取候选区域对应的区域特征 roi_feature = im_feature[:, fy: fy + fh, fx: fx + fw] # 将区域特征池化到固定大小 roi_feature = self.pool(roi_feature) # 将池化后特征展开方便后续送入分类器和回归器 roi_feature = roi_feature.view(-1) roi_features.append(roi_feature) # 转换成tensor roi_features = torch.stack(roi_features) return roi_features复制
其中
# 自适应最大值池化将推荐区域特征池化到固定大小 self.pool = nn.AdaptiveMaxPool2d((self.pool_size, self.pool_size))复制
分类器和回归器是全连接层结构,由于vgg16_bn输出通道为512,经过区域池化后特征长宽固定,因此将其定义如下:
# 分类器, 输入为vgg16的512通道特征经过roi_pool的结果 self.classifier = nn.Sequential( nn.Linear(in_features=512 * self.pool_size * self.pool_size, out_features=32), nn.ReLU(), nn.Dropout(p=drop), nn.Linear(in_features=32, out_features=num_classes) ) # 回归器, 输入为vgg16的512通道特征经过roi_pool的结果 self.regressor = nn.Sequential( nn.Linear(in_features=512 * self.pool_size * self.pool_size, out_features=64), nn.ReLU(), nn.Dropout(p=drop), nn.Linear(in_features=64, out_features=4) )复制
Fast RCNN损失函数由分类损失(CrossEntropy Loss)和回归损失(SmoothL1 Loss)两部分构成。其中分类模型需要区分候选区域类别,以判定物体还是背景,因此需要对所有输出进行计算损失。回归模型只需要对物体边界框进行矫正,因此只计算非背景区域的损失。
多任务损失代码如下:
def multitask_loss(output: tuple, labels: Tensor, offsets: Tensor, criterion: list, alpha: float = 1.0): """ 计算多任务损失 :param output: 模型输出 :param labels: 边界框标签 :param offsets: 边界框偏移值 :param criterion: 损失函数 :param alpha: 损失函数 :return: """ output_cls, output_reg = output # 计算分类损失 loss_cls = criterion[0](output_cls, labels) # 计算正样本的回归损失 output_reg_valid = output_reg[labels != 0] offsets_valid = offsets[labels != 0] loss_reg = criterion[1](output_reg_valid, offsets_valid) # 损失加权 loss = loss_cls + alpha * loss_reg return loss复制
Fast RCNN无需RCNN那样分阶段的繁琐训练,直接同时训练特征提取器、分类器和回归器。
模型训练阶段代码如下:
# Train.py import os import matplotlib.pyplot as plt import numpy as np import torch from torch import nn from torch.optim.lr_scheduler import StepLR from Utils import FastRCNN, GenDataSet from torch import Tensor from Config import * def multitask_loss(output: tuple, labels: Tensor, offsets: Tensor, criterion: list, alpha: float = 1.0): """ 计算多任务损失 :param output: 模型输出 :param labels: 边界框标签 :param offsets: 边界框偏移值 :param criterion: 损失函数 :param alpha: 损失函数 :return: """ output_cls, output_reg = output # 计算分类损失 loss_cls = criterion[0](output_cls, labels) # 计算正样本的回归损失 output_reg_valid = output_reg[labels != 0] offsets_valid = offsets[labels != 0] loss_reg = criterion[1](output_reg_valid, offsets_valid) # 损失加权 loss = loss_cls + alpha * loss_reg return loss def train(data_set, network, num_epochs, optimizer, scheduler, criterion, device, train_rate=0.8): """ 模型训练 :param data_set: 训练数据集 :param network: 网络结构 :param num_epochs: 训练轮次 :param optimizer: 优化器 :param scheduler: 学习率调度器 :param criterion: 损失函数 :param device: CPU/GPU :param train_rate: 训练集比例 :return: None """ os.makedirs('./model', exist_ok=True) network = network.to(device) best_loss = np.inf print("=" * 8 + "开始训练模型" + "=" * 8) # 计算训练batch数量 batch_num = len(data_set) train_batch_num = round(batch_num * train_rate) # 记录训练过程中每一轮损失和准确率 train_loss_all, val_loss_all, train_acc_all, val_acc_all = [], [], [], [] for epoch in range(num_epochs): # 记录train/val分类准确率和总损失 num_train_acc = num_val_acc = num_train_loss = num_val_loss = 0 train_loss = val_loss = 0.0 train_corrects = val_corrects = 0 for step, batch_data in enumerate(data_set): # 读取数据 ims, labels, ss_boxes, offsets = batch_data ims = ims.to(device) labels = labels.to(device) ss_boxes = [ss.to(device) for ss in ss_boxes] offsets = offsets.to(device) # 模型输入为全图和推荐区域边界框, 即[ims: Tensor, ss_boxes: list[Tensor]] inputs = [ims, ss_boxes] if step < train_batch_num: # train network.train() output = network(inputs) loss = multitask_loss(output=output, labels=labels, offsets=offsets, criterion=criterion) optimizer.zero_grad() loss.backward() optimizer.step() # 计算每个batch分类正确的数量和loss label_hat = torch.argmax(output[0], dim=1) train_corrects += (label_hat == labels).sum().item() num_train_acc += labels.size(0) # 计算每个batch总损失 train_loss += loss.item() * ims.size(0) num_train_loss += ims.size(0) else: # validation network.eval() with torch.no_grad(): output = network(inputs) loss = multitask_loss(output=output, labels=labels, offsets=offsets, criterion=criterion) # 计算每个batch分类正确的数量和loss和 label_hat = torch.argmax(output[0], dim=1) val_corrects += (label_hat == labels).sum().item() num_val_acc += labels.size(0) val_loss += loss.item() * ims.size(0) num_val_loss += ims.size(0) scheduler.step() # 记录loss和acc变化曲线 train_loss_all.append(train_loss / num_train_loss) val_loss_all.append(val_loss / num_val_loss) train_acc_all.append(100 * train_corrects / num_train_acc) val_acc_all.append(100 * val_corrects / num_val_acc) print("Epoch:[{:0>3}|{}] train_loss:{:.3f} train_acc:{:.2f}% val_loss:{:.3f} val_acc:{:.2f}%".format( epoch + 1, num_epochs, train_loss_all[-1], train_acc_all[-1], val_loss_all[-1], val_acc_all[-1] )) # 保存模型 if val_loss_all[-1] < best_loss: best_loss = val_loss_all[-1] save_path = os.path.join("./model", "model.pth") torch.save(network, save_path) # 绘制训练曲线 fig_path = os.path.join("./model/", "train_curve.png") plt.subplot(121) plt.plot(range(num_epochs), train_loss_all, "r-", label="train") plt.plot(range(num_epochs), val_loss_all, "b-", label="val") plt.title("Loss") plt.legend() plt.subplot(122) plt.plot(range(num_epochs), train_acc_all, "r-", label="train") plt.plot(range(num_epochs), val_acc_all, "b-", label="val") plt.title("Acc") plt.legend() plt.tight_layout() plt.savefig(fig_path) plt.close() return None if __name__ == "__main__": if not os.path.exists("./data/ss"): raise FileNotFoundError("数据不存在, 请先运行SelectiveSearch.py生成目标区域") device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = FastRCNN(num_classes=CLASSES, in_size=IM_SIZE, pool_size=POOL_SIZE, spatial_scale=SCALE, device=device) exit(0) criterion = [nn.CrossEntropyLoss(), nn.SmoothL1Loss()] optimizer = torch.optim.Adam(params=model.parameters(), lr=LR) scheduler = StepLR(optimizer, step_size=STEP, gamma=GAMMA) model_root = "./model" os.makedirs(model_root, exist_ok=True) # 在生成的ss数据上进行预训练 train_root = "./data/ss" train_set = GenDataSet(root=train_root, im_width=IM_SIZE, im_height=IM_SIZE, batch_size=BATCH_SIZE, shuffle=True) train(data_set=train_set, network=model, num_epochs=EPOCHS, optimizer=optimizer, scheduler=scheduler, criterion=criterion, device=device)复制
通过上述流程,训练好了Fast RCNN模型。可以输入图片对目标进行预测,但是有三点值得注意:
a. 模型输出包含分类和回归两部分结果,其中回归器输出为边界框的偏移值,需要利用偏移值对推荐区域位置先进性修正;
b. 模型输入被resize到了 [3, 512, 512] ,预测得到的边界框位置也是相对于缩放后图像,需要重新映射到原图中;
c. 预测结果中可能存在很多冗余边界框,需要设计去除。
2.2中已经介绍边界框偏移值是采用比例和对数方式计算,现在只需反向操作即可根据偏移值和推荐边界框计算出修正后的结果。
边界框位置修正代码如下:
def rectify_bbox(ss_boxes: np.ndarray, offsets: np.ndarray) -> np.ndarray: """ 修正边界框位置 :param ss_boxes: 边界框 :param offsets: 边界框偏移值 :return: 位置修正后的边界框 """ # 和Utils.GenDataSet.calc_offsets过程相反 ss_boxes[:, 0] = ss_boxes[:, 2] * offsets[:, 0] + ss_boxes[:, 0] ss_boxes[:, 1] = ss_boxes[:, 3] * offsets[:, 1] + ss_boxes[:, 1] ss_boxes[:, 2] = np.exp(offsets[:, 2]) * ss_boxes[:, 2] ss_boxes[:, 3] = np.exp(offsets[:, 3]) * ss_boxes[:, 3] boxes = ss_boxes.astype("int") return boxes复制
模型输入数据是经过resize方式得到的,在边界框映射回原图时,也只需要计算缩放比例反向映射即可。
边界框位置映射代码如下:
def map_bbox_to_img(boxes: np.ndarray, src_img: np.ndarray, im_width: int, im_height: int): """ 根据缩放比例将边界框映射回原图 :param boxes: 缩放后图像上的边界框 :param src_img: 原始图像 :param im_width: 缩放后图像宽度 :param im_height: 缩放后图像高度 :return: boxes->映射到原图像上的边界框 """ rows, cols = src_img.shape[:2] scale_ratio = np.array([cols / im_width, rows / im_height, cols / im_width, rows / im_height]) boxes = (boxes * scale_ratio).astype("int") return boxes复制
和RCNN一样,Fast RCNN也通过ss方法产生大量的候选区域(~2k)。虽然分类器能够去除大量背景区域,但是仍然有较多的目标区域,会得较多的目标检测框。这些检测框大部分都是重叠的,需要进行筛选。非极大值抑制(Non-Maximum Supression,后续称之为 nms)就是一种候选框选取方法。
非极大值抑制通过目标置信度对边界框进行筛选,其具体流程如下:
(1)初始化输出列表 out_bboxes = [ ];
(2)获取输入边界框 in_bboxes 对应的目标类别置信度;
(3)将照置信度由高到低的方式对边界框进行排序;
(4)选取置信度最高的边界框 bbox_max,将其添加到 out_bboxes 中,并计算它与其他边界框的IoU结果;
(5)IoU大于阈值的表明两区域较为接近,边界框重叠性较高,将这些框和bbox_max从 in_bboxes 中移除;
(6)重复执行3~5过程,直到 in_bboxes 为空,此时 out_bboxes 即最终保留的边界框结果。
非极大值抑制的代码实现如下:
def nms(bboxes: np.ndarray, scores: np.ndarray, threshold: float) -> np.ndarray: """ 非极大值抑制去除冗余边界框 :param bboxes: 目标边界框 :param scores: 目标得分 :param threshold: 阈值 :return: keep->保留下的有效边界框 """ # 获取边界框和分数 x1 = bboxes[:, 0] y1 = bboxes[:, 1] x2 = bboxes[:, 0] + bboxes[:, 2] - 1 y2 = bboxes[:, 1] + bboxes[:, 3] - 1 # 计算面积 areas = (x2 - x1 + 1) * (y2 - y1 + 1) # 逆序排序 order = scores.argsort()[::-1] keep = [] while order.size > 0: # 取分数最高的一个 i = order[0] keep.append(bboxes[i]) if order.size == 1: break # 计算相交区域 xx1 = np.maximum(x1[i], x1[order[1:]]) xx2 = np.minimum(x2[i], x2[order[1:]]) yy1 = np.maximum(y1[i], y1[order[1:]]) yy2 = np.minimum(y2[i], y2[order[1:]]) # 计算IoU inter = np.maximum(0.0, xx2 - xx1 + 1) * np.maximum(0.0, yy2 - yy1 + 1) iou = inter / (areas[i] + areas[order[1:]] - inter) # 保留IoU小于阈值的bbox idx = np.where(iou <= threshold)[0] order = order[idx + 1] keep = np.array(keep) return keep复制
如下,左图为未采用nms边界框结果,右图为nms处理后结果,表明nms能够较好地去除冗余边界框。


结合上述流程,可以完成Fast RCNN对目标的预测,其预测阶段代码如下:
# Predict.py import os import torch import numpy as np import skimage.io as io from Utils import GenDataSet, draw_box from torch.nn.functional import softmax from SelectiveSearch import SelectiveSearch as ss from Config import * def rectify_bbox(ss_boxes: np.ndarray, offsets: np.ndarray) -> np.ndarray: """ 修正边界框位置 :param ss_boxes: 边界框 :param offsets: 边界框偏移值 :return: 位置修正后的边界框 """ # 和Utils.GenDataSet.calc_offsets过程相反 ss_boxes = ss_boxes.astype("float32") ss_boxes[:, 0] = ss_boxes[:, 2] * offsets[:, 0] + ss_boxes[:, 0] ss_boxes[:, 1] = ss_boxes[:, 3] * offsets[:, 1] + ss_boxes[:, 1] ss_boxes[:, 2] = np.exp(offsets[:, 2]) * ss_boxes[:, 2] ss_boxes[:, 3] = np.exp(offsets[:, 3]) * ss_boxes[:, 3] boxes = ss_boxes.astype("int") return boxes def map_bbox_to_img(boxes: np.ndarray, src_img: np.ndarray, im_width: int, im_height: int): """ 根据缩放比例将边界框映射回原图 :param boxes: 缩放后图像上的边界框 :param src_img: 原始图像 :param im_width: 缩放后图像宽度 :param im_height: 缩放后图像高度 :return: boxes->映射到原图像上的边界框 """ rows, cols = src_img.shape[:2] scale_ratio = np.array([cols / im_width, rows / im_height, cols / im_width, rows / im_height]) boxes = (boxes * scale_ratio).astype("int") return boxes def nms(bboxes: np.ndarray, scores: np.ndarray, threshold: float) -> np.ndarray: """ 非极大值抑制去除冗余边界框 :param bboxes: 目标边界框 :param scores: 目标得分 :param threshold: 阈值 :return: keep->保留下的有效边界框 """ # 获取边界框和分数 x1 = bboxes[:, 0] y1 = bboxes[:, 1] x2 = bboxes[:, 0] + bboxes[:, 2] - 1 y2 = bboxes[:, 1] + bboxes[:, 3] - 1 # 计算面积 areas = (x2 - x1 + 1) * (y2 - y1 + 1) # 逆序排序 order = scores.argsort()[::-1] keep = [] while order.size > 0: # 取分数最高的一个 i = order[0] keep.append(bboxes[i]) if order.size == 1: break # 计算相交区域 xx1 = np.maximum(x1[i], x1[order[1:]]) xx2 = np.minimum(x2[i], x2[order[1:]]) yy1 = np.maximum(y1[i], y1[order[1:]]) yy2 = np.minimum(y2[i], y2[order[1:]]) # 计算IoU inter = np.maximum(0.0, xx2 - xx1 + 1) * np.maximum(0.0, yy2 - yy1 + 1) iou = inter / (areas[i] + areas[order[1:]] - inter) # 保留IoU小于阈值的bbox idx = np.where(iou <= threshold)[0] order = order[idx + 1] keep = np.array(keep) return keep def predict(network, im, im_width, im_height, device, nms_thresh=None, save_name=None): """ 模型预测 :param network: 模型结构 :param im: 输入图像 :param im_width: 模型输入图像宽度 :param im_height: 模型输入图像长度 :param device: CPU/GPU :param nms_thresh: 非极大值抑制阈值 :param save_name: 保存文件名 :return: None """ network.eval() # 生成推荐区域 ss_boxes_src = ss.cal_proposals(img=im) # 数据归一化 im_norm = GenDataSet.normalize(im=im) # 将图像缩放固定大小, 并将边界框映射到缩放后图像上 im_rsz, ss_boxes_rsz = GenDataSet.resize(im=im_norm, im_width=im_width, im_height=im_height, ss_boxes=ss_boxes_src, gt_boxes=None) im_tensor = torch.tensor(np.transpose(im_rsz, (2, 0, 1))).unsqueeze(0).to(device) ss_boxes_tensor = torch.tensor(ss_boxes_rsz).to(device) # 模型输入为[img: Tensor, ss_boxes: list(Tensor)] inputs = [im_tensor, [ss_boxes_tensor]] with torch.no_grad(): outputs = network(inputs) # 计算各个类别的分类得分 scores = softmax(input=outputs[0], dim=1) scores = scores.cpu().numpy() # 获取位置偏移 offsets = outputs[1] offsets = offsets.cpu().numpy() # 根据模型计算出的offsets对推荐区域边界框位置进行修正 out_boxes = rectify_bbox(ss_boxes=ss_boxes_rsz, offsets=offsets) # 将边界框位置映射回原始图像 out_boxes = map_bbox_to_img(boxes=out_boxes, src_img=im, im_width=im_width, im_height=im_height) # 边界框筛选 predicted_boxes = [] for i in range(1, CLASSES): # 获取当前类别目标得分 cur_obj_scores = scores[:, i] # 只选取置信度满足阈值要求的预测框 idx = cur_obj_scores >= CONFIDENCE_THRESH valid_scores = cur_obj_scores[idx] valid_out_boxes = out_boxes[idx] # 遍历物体类别, 对每个类别的边界框预测结果进行非极大值抑制 if nms_thresh is not None: used_boxes = nms(bboxes=valid_out_boxes, scores=valid_scores, threshold=nms_thresh) else: used_boxes = valid_out_boxes # 可能存在值不符合要求的情况, 需要剔除 for j in range(used_boxes.shape[0]): if used_boxes[j, 0] < 0 or used_boxes[j, 1] < 0 or used_boxes[j, 2] <= 0 or used_boxes[j, 3] <= 0: continue predicted_boxes.append(used_boxes[j]) draw_box(img=im, boxes=predicted_boxes, save_name=save_name) return None if __name__ == "__main__": device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model_path = "./model/model.pth" model = torch.load(model_path, map_location=device) test_root = "./data/" for roots, dirs, files in os.walk(test_root): for file in files: if not file.endswith(".jpg"): continue save_name = file.split(".")[0] im_path = os.path.join(roots, file) im = io.imread(im_path) predict(network=model, im=im, im_width=IM_SIZE, im_height=IM_SIZE, device=device, nms_thresh=NMS_THRESH, save_name=save_name)复制
如下为Fast RCNN在花朵数据集上预测结果展示,左图中当同一图中存在多个相同类别目标且距离较近时,边界框并没有很好地检测出每个个体。

相较于RCNN算法,Fast RCNN算法极大的缩短了检测时间,但是整个过程仍需要使用ss方法生成候选区域,总体时间消耗仍然不适用于实时检测任务。
本文中数据和详细工程代码实现请移步:https://github.com/jchsun1/Fast-RCNN
Reference:
本文结束,祝君好运。